27 Ένας οδηγός για το βασικό σύνολο λειτουργιών της R
27.1 Εισαγωγή
Ως επίλογο της ενότητας του προγραμματισμού, θα σας δώσουμε μία ιδέα για τις πιο σημαντικές βασικές συναρτήσεις της R που διαφορετικά δεν θα συζητούσαμε σε αυτό το βιβλίο. Τα εργαλεία αυτά είναι αρκετά χρήσιμα όσο προγραμματίζετε περισσότερο και θα σας βοηθήσουν στο να διαβάζετε κώδικα που κυκλοφορεί εκεί έξω.
Σε αυτό το σημείο είναι καλό να σας υπενθυμίσουμε ότι το tidyverse δεν υπάρχει μόνο για να αντιμετωπίζει προβλήματα της επιστήμης δεδομένων. Δείχνουμε το tidyverse σε αυτό το βιβλίο επειδή τα αντίστοιχα πακέτα του μοιράζονται μία κοινή φιλοσοφία, αυξάνοντας τη συνοχή μεταξύ των συναρτήσεων και καθιστώντας κάθε νέα συνάρτηση ή πακέτο λίγο πιο εύκολα στην εκμάθηση και χρήση. Δεν είναι δυνατό να χρησιμοποιήσετε το tidyverse χωρίς τη χρήση των βασικών συναρτήσεων της R. Σας έχουμε ήδη μάθει πολλές βασικές συναρτήσεις R: από την library() για την φόρτωση πακέτων, τη sum() και τη mean() για αριθμητικές περιλήψεις, για τους τύπους δεδομένων με παράγοντες (factors), ημερομηνίες και POSIXct και φυσικά όλους τους βασικούς τελεστές όπως +, -, /, *, |, &, και !. Αυτό στο οποίο δεν έχουμε επικεντρωθεί μέχρι στιγμής είναι οι βασικές ροές εργασίας της R, επομένως θα επισημάνουμε μερικές από αυτές σε αυτό το κεφάλαιο.
Αφού διαβάσετε αυτό το βιβλίο, θα μάθετε και άλλες προσεγγίσεις πάνω στα ίδια προβλήματα χρησιμοποιώντας το βασικό σύνολο λειτουργιών της R, το data.table και άλλα πακέτα. Θα συναντήσετε αυτές τις άλλες προσεγγίσεις χωρίς αμφιβολία όταν αρχίσετε να διαβάζετε κώδικα R που γράφτηκε από άλλους, ιδιαίτερα εάν χρησιμοποιείτε το StackOverflow. Είναι 100% εντάξει να γράφετε κώδικα που χρησιμοποιεί έναν συνδυασμό προσεγγίσεων και μην αφήνετε κανέναν να σας πει το αντίθετο!
Σε αυτό το κεφάλαιο, θα εστιάσουμε σε τέσσερις μεγάλες θεματολογίες: δημιουργία υποσυνόλων με [, δημιουργία υποσυνόλων με τα [[ και $, την οικογένεια συναρτήσεων apply και βρόγχους for. Τέλος, θα συζητήσουμε εν συντομία δύο συναρτήσεις δημιουργίας διαγραμμάτων.
27.1.1 Προαπαιτούμενα
Το πακέτο αυτό εστιάζει στις βασικές λειτουργίες της R, επομένως δεν έχει πραγματικά προαπαιτούμενα, αλλά θα φορτώσουμε το tidyverse για να εξηγήσουμε μερικές διαφορές.
27.2 Επιλογή πολλαπλών στοιχείων με [
Το [ χρησιμοποιείται για την εξαγωγή υποσυνόλων από διανύσματα και πλαίσια δεδομένων και καλείται ως x[i] ή x[i, j]. Σε αυτήν την ενότητα, θα σας παρουσιάσουμε τις ικανότητες του [, δείχνοντάς σας πρώτα πώς μπορείτε να το χρησιμοποιήσετε με διανύσματα και στη συνέχεια πως οι ίδιες αρχές επεκτείνονται με απλό τρόπο στις δύο διαστάσεις όπως στα πλαίσια δεδομένων. Στη συνέχεια, θα σας βοηθήσουμε να το εμπεδώσετε δείχνοντας πώς διάφορες συναρτήσεις της dplyr είναι ειδικές περιπτώσεις του [.
27.2.1 Υποσύνολα από διανύσματα
Υπάρχουν πέντε κύριοι τύποι κατηγοριών με τις οποίες μπορείτε να εξάγετε ένα υποσύνολο από ένα διάνυσμα, δηλαδή πέντε διαφορετικές κατηγορίες που αντιστοιχούν στο i από το x[i]:
-
Διάνυσμα με θετικούς ακέραιους αριθμούς. Η δημιουργία υποσυνόλων με θετικούς ακέραιους αριθμούς επιστρέφει τα στοιχεία των αντίστοιχων θέσεων:
Επαναλαμβάνοντας μία θέση μπορείτε να δημιουργήσετε μία μεγαλύτερη έξοδο, κάνοντας τον όρο “υποσύνολο” ελαφρώς λανθασμένο.
x[c(1, 1, 5, 5, 5, 2)] #> [1] "one" "one" "five" "five" "five" "two" -
Διάνυσμα με αρνητικούς ακέραιους αριθμούς. Αρνητικές τιμές αφαιρούν τα στοιχεία στις αντίστοιχες θέσεις:
x[c(-1, -3, -5)] #> [1] "two" "four" -
Λογικό διάνυσμα. Δημιουργώντας ένα υποσύνολο χρησιμοποιώντας λογικές τιμές επιστρέφει όλες τις τιμές όπου είναι
TRUE. Συχνά, αυτό είναι πιο χρήσιμο σε συνδυασμό με συναρτήσεις σύγκρισης.Σε αντίθεση με την
filter(), οι θέσεις που περιέχουνNAθα συμπεριληφθούν στην έξοδο ωςNA. -
Διάνυσμα χαρακτήρα. Εάν έχετε ένα διάνυσμα με ονόματα για κάθε στοιχείο του, μπορείτε να δημιουργήσετε ένα υποσύνολο με ένα διάνυσμα χαρακτήρα:
Όπως και με τα υποσύνολα από θετικούς ακέραιους αριθμούς, μπορείτε να χρησιμοποιήσετε ένα διάνυσμα χαρακτήρων για να επαναλάβετε μεμονωμένες εγγραφές.
Κενό. Ο τελευταίος τύπος δημιουργίας υποσύνολου είναι το κενό,
x[], το οποίο επιστρέφει ολόκληρο τοx. Δεν είναι χρήσιμο όμως για υποσύνολα διανυσμάτων, αλλά όπως θα δούμε σύντομα, είναι χρήσιμο για υποσύνολα δισδιάστατων δομών, όπως τα tibbles.
27.2.2 Υποσύνολα πλαισίων δεδομένων
Υπάρχουν αρκετοί διαφορετικοί τρόποι1 με τους οποίους μπορείτε να χρησιμοποιήσετε το [ με ένα πλαίσιο δεδομένων, αλλά ο πιο σημαντικός είναι να επιλέξετε γραμμές και στήλες ξεχωριστά χρησιμοποιώντας το df[γραμμές, στήλες]. Εδώ οι γραμμές και οι στήλες είναι διανύσματα όπως περιγράφονται παραπάνω. Για παράδειγμα, τα df[γραμμές, ] και df[, στήλες] επιλέγουν μόνο γραμμές ή μόνο στήλες, χρησιμοποιώντας το κενό υποσύνολο για να διατηρήσουν την άλλη διάσταση.
Μερικά παραδείγματα:
df <- tibble(
x = 1:3,
y = c("a", "e", "f"),
z = runif(3)
)
# Επιλέξτε την πρώτη γραμμή και τη δεύτερη στήλη
df[1, 2]
#> # A tibble: 1 × 1
#> y
#> <chr>
#> 1 a
# Επιλέξτε όλες τις γραμμές και τις στήλες x και y
df[, c("x" , "y")]
#> # A tibble: 3 × 2
#> x y
#> <int> <chr>
#> 1 1 a
#> 2 2 e
#> 3 3 f
# Επιλέξτε γραμμλες όπου το `x` είναι μεγαλύτερο από 1 και όλες οι στήλες
df[df$x > 1, ]
#> # A tibble: 2 × 3
#> x y z
#> <int> <chr> <dbl>
#> 1 2 e 0.834
#> 2 3 f 0.601Θα επανέλθουμε σύντομα στο $, θα πρέπει όμως να μπορείτε να μαντέψετε ήδη τι κάνει το df$x από τα συμφραζόμενα: εξάγει τη μεταβλητή x από το df. Εδώ, πρέπει να το χρησιμοποιήσουμε επειδή το [ δεν χρησιμοποιεί αξιολόγηση tidy, επομένως πρέπει να είστε ξεκάθαροι σχετικά με την πηγή της μεταβλητής x.
Υπάρχει μία σημαντική διαφορά μεταξύ των tibbles και των πλαισίων δεδομένων όσον αφορά το [. Σε αυτό το βιβλίο, χρησιμοποιήσαμε κυρίως τα tibbles, τα οποία είναι πλαίσια δεδομένων, αλλά τροποποιούν ορισμένες συμπεριφορές για να κάνουν τη ζωή σας λίγο πιο εύκολη. Στα περισσότερα σημεία, μπορείτε να χρησιμοποιήσετε είτε το “tibble” είτε το “data frame” (πλαίσιο δεδομένων), οπότε όταν θέλουμε να δώσουμε έμφαση στο ενσωματωμένο πλαίσιο δεδομένων της R, θα γράφουμε data.frame. Εάν το df είναι ένα data.frame, τότε το df[, cols] θα επιστρέψει ένα διάνυσμα εάν το col επιλέγει μία στήλη, και ένα πλαίσιο δεδομένων εάν επιλέγει περισσότερες από μία στήλες. Εάν το df είναι tibble, τότε η χρήση του [ θα επιστρέφει πάντα ένα tibble.
df1 <- data.frame(x = 1:3)
df1[, "x"]
#> [1] 1 2 3
df2 <- tibble(x = 1:3)
df2[, "x"]
#> # A tibble: 3 × 1
#> x
#> <int>
#> 1 1
#> 2 2
#> 3 3Ένας τρόπος για να αποφύγετε αυτή την ασάφεια με τα data.frame είναι να θέτετε το όρισμα drop = FALSE:
df1[, "x" , drop = FALSE]
#> x
#> 1 1
#> 2 2
#> 3 327.2.3 Ισοδύναμα της dplyr
Αρκετές συναρτήσεις της dplyr είναι ειδικές περιπτώσεις του [:
-
Η
filter()ισοδυναμεί με το να δημιουργείτε υποσύνολα γραμμών χρησιμοποιώντας ένα λογικό διάνυσμα ενώ ταυτόχρονα εξαιρείτε τις κενές τιμές:Μία άλλη γνωστή τεχνική είναι η χρήση της
which(), εξαιτίας της ιδιότητάς της να εξαιρεί κενές τιμές:df[which(df$x > 1), ]. -
Η
arrange()ισοδυναμεί με την αναδιοργάνωση των γραμμών χρησιμοποιώντας ένα διάνυσμα ακέραιου αριθμού. Συνήθως γίνεται με τηνorder():Μπορείτε να χρησιμοποιήσετε το
order(decreasing = TRUE)για να ταξινομήσετε όλες τις στήλες με φθίνουσα σειρά ή το-rank(col)για να ταξινομήσετε τις στήλες με φθίνουσα μία προς μία. -
Τόσο η
select()όσο και ηrelocate()είναι παρόμοιες με το να δημιουργείτε υποσύνολα στηλών χρησιμοποιώντας ένα διάνυσμα χαρακτήρων:
Το βασικό σύνολο της R προσφέρει μία συνάρτηση η οποία συνδυάζει τα χαρακτηριστικά της filter() και της select()2 και ονομάζεται subset():
Η συνάρτηση αυτή ήταν η έμπνευση για ένα αρκετά μεγάλο μέρος του συντακτικού της dplyr.
27.2.4 Ασκήσεις
-
Δημιουργήστε συναρτήσεις οι οποίες παίρνουν ως είσοδο ένα διάνυσμα και επιστρέφουν:
α. Τα στοιχεία που βρίσκονται σε ζυγές θέσεις. β. Όλα τα στοιχεία εκτός του τελευταίου. γ. Μόνο ζυγές τιμές (και όχι κενές τιμές). Γιατί το
x[-which(x > 0)]δεν είναι το ίδιο με τοx[x <= 0]; Διαβάστε τις οδηγίες για τηνwhich()και πειραματιστείτε για να το βρείτε.
27.3 Επιλέγοντας μόνο ένα στοιχείο με το $ και το [[
Το [, το οποίο επιλέγει πολλαπλά στοιχεία, συνδυάζεται με τα [[ και $, τα οποία εξάγουν ένα μεμονωμένο στοιχείο. Σε αυτήν την ενότητα, θα σας δείξουμε πώς να χρησιμοποιείτε τα [[ και $ για να εξάγετε στήλες από τα πλαίσια δεδομένων, θα συζητήσουμε μερικές ακόμη διαφορές μεταξύ των data.frame και των tibbles και θα τονίσουμε μερικές σημαντικές διαφορές μεταξύ του [ και του [[ όταν χρησιμοποιούνται με λίστες.
27.3.1 Πλαίσια δεδομένων
Τα [[ και $ μπορούν να χρησιμοποιηθούν για την εξαγωγή στηλών από ένα πλαίσιο δεδομένων. Το [[ μπορεί να έχει πρόσβαση σε δομές δεδομένων με βάση τη θέση ή το όνομα, και το $ είναι ειδικά για πρόσβαση με βάση το όνομα:
Μπορούν να χρησιμοποιηθούν και για τη δημιουργία νέων στηλών. Το αντίστοιχο της mutate() στο βασικό σύνολο της R είναι:
tb$z <- tb$x + tb$y
tb
#> # A tibble: 4 × 3
#> x y z
#> <int> <dbl> <dbl>
#> 1 1 10 11
#> 2 2 4 6
#> 3 3 1 4
#> 4 4 21 25Υπάρχουν πολλές άλλες προσεγγίσεις του βασικού συνόλου της R για τη δημιουργία νέων στηλών, συμπεριλαμβανομένων των transform(), with() και within(). Ο Hadley συγκέντρωσε μερικά παραδείγματα στη διεύθυνση https://gist.github.com/hadley/1986a273e384fb2d4d752c18ed71bedf.
Η απευθείας χρήση του $ είναι βολική για την κατασκευή γρήγορων περιλήψεων. Για παράδειγμα, εάν θέλετε απλώς να βρείτε το μέγεθος του μεγαλύτερου διαμαντιού ή τις πιθανές τιμές της cut, δεν χρειάζεται να χρησιμοποιήσετε την summarize():
Η dplyr παρέχει επίσης ένα ισοδύναμο με το [[/$ που δεν αναφέραμε στο Κεφάλαιο 3: την pull(). Η pull() παίρνει είτε ένα όνομα μεταβλητής είτε μία θέση μεταβλητής και επιστρέφει ακριβώς αυτήν τη στήλη. Αυτό σημαίνει ότι θα μπορούσαμε να ξαναγράψουμε τον παραπάνω κώδικα για να χρησιμοποιήσουμε το pipe:
27.3.2 Tibbles
Υπάρχουν μερικές σημαντικές διαφορές μεταξύ των tibbles και του βασικού data.frame όσον αφορά το $. Στα πλαίσια δεδομένων αρκεί να ταιριάξει το πρόθεμα οποιουδήποτε ονόματος μεταβλητής (η λεγόμενη μερική αντιστοίχιση) και δεν παραπονιέται εάν η στήλη δεν υπάρχει:
df <- data.frame(x1 = 1)
df$x
#> [1] 1
df$z
#> NULLΤα tibbles είναι πιο αυστηρά: τα ονόματα των μεταβλητών πρέπει να ταιριάζουν ακριβώς και θα επιστρέψουν μία προειδοποίηση εάν η στήλη στην οποία προσπαθείτε να αποκτήσετε πρόσβαση δεν υπάρχει:
tb <- tibble(x1 = 1)
tb$x
#> Warning: Unknown or uninitialised column: `x`.
#> NULL
tb$z
#> Warning: Unknown or uninitialised column: `z`.
#> NULLΓια αυτόν τον λόγο, μερικές φορές αστειευόμαστε ότι τα tibbles είναι τεμπέλικα και κακόκεφα: κάνουν λίγα και παραπονιούνται περισσότερο.
27.3.3 Λίστες
Τα [[ και $ είναι επίσης πολύ σημαντικά για εργασίες με λίστες και είναι σημαντικό να κατανοήσουμε πώς διαφέρουν από το [. Ας δείξουμε τις διαφορές με μία λίστα με όνομα l:
-
Το
[εξάγει μία υπο-λίστα. Δεν έχει σημασία πόσα στοιχεία θα εξάγετε, το αποτέλεσμα θα είναι πάντα λίστα.Όπως και με τα διανύσματα, μπορείτε να δημιουργήσετε υποσύνολα χρησιμοποιώντας διανύσματα λογικών τιμών, ακέραιων αριθμών ή χαρακτήρων.
-
Τα
[[και$εξάγουν ένα μόνο στοιχείο από μία λίστα. Αφαιρούν ένα επίπεδο από τη λίστα.
Η διαφορά μεταξύ [ και [[ είναι ιδιαίτερα σημαντική για τις λίστες, επειδή το [[ εμβαθύνει στη λίστα ενώ το [ επιστρέφει μία νέα, μικρότερη λίστα. Για να σας βοηθήσουμε να θυμάστε τη διαφορά, ρίξτε μία ματιά στην ασυνήθιστη πιπεριέρα στο Σχήμα 27.1. Εάν η πιπεριέρα είναι η λίστα σας με όνομα pepper, τότε, το pepper[1] είναι μία πιπεριέρα που περιέχει ένα μόνο φακελάκι πιπεριού. Το pepper[2] θα ήταν το ίδιο, αλλά θα περιέχει το δεύτερο φακελάκι. Το pepper[1:2] θα ήταν μία πιπεριέρα με δύο φακελάκια πιπεριού. Το pepper[[1]] θα εξάγει το ίδιο το φακελάκι πιπεριού.
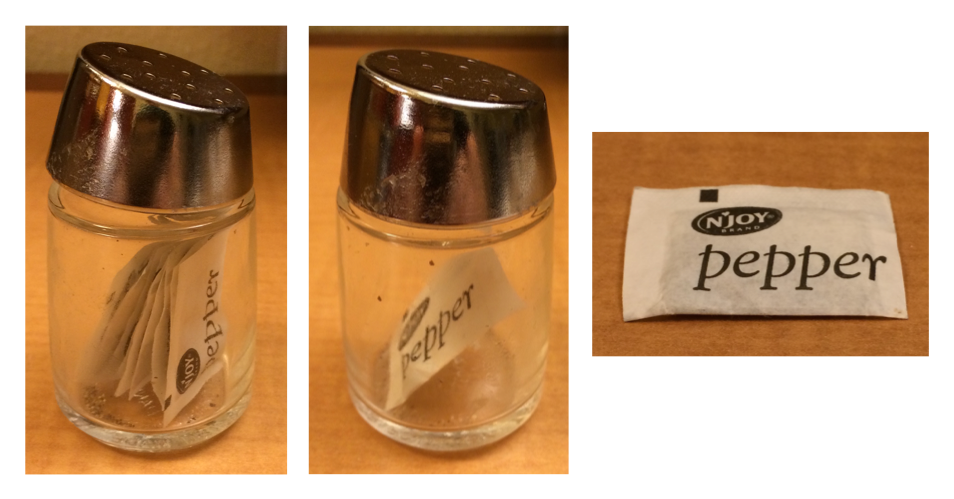
pepper[1]. (Δεξιά) pepper[[1]]
Η ίδια αρχή ισχύει όταν χρησιμοποιείτε το μονοδιάστατο [ σε ένα πλαίσιο δεδομένων: το df["x"] επιστρέφει ένα πλαίσιο δεδομένων μίας στήλης και το df[["x"]] επιστρέφει ένα διάνυσμα.
27.3.4 Ασκήσεις
Τι συμβαίνει όταν χρησιμοποιείτε το
[[με έναν θετικό ακέραιο που είναι μεγαλύτερος από το μήκος του διανύσματος; Τι συμβαίνει όταν δημιουργείτε ένα υποσυνόλου χρησιμοποιώντας ένα όνομα που δεν υπάρχει;Τι θα μπορούσε να είναι το
pepper[[1]][1]; Τοpepper[[1]][[1]];
27.4 Οικογένεια συναρτήσεων apply
Στο Κεφάλαιο 26, μάθατε τεχνικές σχετικές με το tidyverse για επανάληψη, όπως την dplyr::across() και την οικογένεια συναρτήσεων map. Σε αυτήν την ενότητα, θα μάθετε για τα βασικά τους ισοδύναμα, την οικογένεια συναρτήσεων apply. Σε αυτό το πλαίσιο, η apply και η map είναι συνώνυμες επειδή ένας άλλος τρόπος να πούμε “αντιστοίχιση (map) μιας συνάρτησης σε κάθε στοιχείο ενός διανύσματος” είναι “εφαρμογή (apply) μιας συνάρτησης σε κάθε στοιχείο ενός διανύσματος”. Εδώ θα σας δώσουμε μία γρήγορη επισκόπηση αυτής της οικογένειας συναρτήσεων, ώστε να μπορείτε να την αναγνωρίσετε εκεί έξω.
Το πιο σημαντικό μέλος αυτής της οικογένειας είναι η lapply(), η οποία μοιάζει πολύ με τη purrr::map()3. Στην πραγματικότητα, επειδή δεν έχουμε χρησιμοποιήσει καμία από τις πιο προχωρημένες δυνατότητες της map(), μπορείτε να αντικαταστήσετε κάθε κλήση της map() στο Κεφάλαιο 26 με την lapply().
Δεν υπάρχει ακριβής αντιστοίχιση του βασικού συνόλου λειτουργιών της R με την across(), αλλά μπορείτε να έρθετε αρκετά κοντά χρησιμοποιώντας το [ με την lapply(). Αυτό λειτουργεί επειδή στο παρασκήνιο, τα πλαίσια δεδομένων είναι λίστες στηλών, επομένως η κλήση της lapply() σε ένα πλαίσιο δεδομένων εφαρμόζει τη συνάρτηση σε κάθε στήλη.
df <- tibble(a = 1, b = 2, c = "a", d = "b", e = 4)
# Πρώτα βρείτε τις αριθμητικές στήλες
num_cols <- sapply(df, is.numeric)
num_cols
#> a b c d e
#> TRUE TRUE FALSE FALSE TRUE
# Στη συνέχεια, αλλάξτε κάθε στήλη με την lapply() και αντικαταστήστε τις αρχικές τιμές
df[, num_cols] <- lapply(df[, num_cols, drop = FALSE], \(x) x * 2)
df
#> # A tibble: 1 × 5
#> a b c d e
#> <dbl> <dbl> <chr> <chr> <dbl>
#> 1 2 4 a b 8Ο παραπάνω κώδικας χρησιμοποιεί μία νέα συνάρτηση, την sapply(). Είναι παρόμοια με την lapply(), αλλά προσπαθεί πάντα να απλοποιήσει το αποτέλεσμα, εξ ου και το s στο όνομά της. Εδώ παράγει ένα λογικό διάνυσμα αντί για μία λίστα. Δεν συνιστούμε να τη χρησιμοποιήσετε για τη δημιουργία προγραμμάτων, επειδή η απλοποίηση μπορεί να αποτύχει και να σας δώσει έναν απροσδόκητο τύπο δεδομένων. Συνήθως όμως είναι καλή για διαδραστική χρήση. Η purrr έχει μία παρόμοια συνάρτηση που ονομάζεται map_vec() που δεν αναφέραμε στο Κεφάλαιο 26.
Το βασικό σύνολο της R παρέχει μία πιο αυστηρή έκδοση της sapply() που ονομάζεται vapply(), συντομογραφία για το vector apply. Παίρνει ένα πρόσθετο όρισμα που καθορίζει τον αναμενόμενο τύπο, διασφαλίζοντας ότι η απλοποίηση γίνεται με τον ίδιο τρόπο ανεξάρτητα από την είσοδο. Για παράδειγμα, θα μπορούσαμε να αντικαταστήσουμε την κλήση της sapply() παραπάνω με αυτήν της vapply() όπου προσδιορίζουμε ότι αναμένουμε από την is.numeric() να επιστρέψει ένα λογικό διάνυσμα μήκους 1:
Η διαφορά μεταξύ των sapply() και vapply() είναι πολύ σημαντική όταν βρίσκονται μέσα σε μία συνάρτηση (καθώς επηρεάζεται η ανθεκτικότητα της συνάρτησης σε ασυνήθιστες εισόδους), αλλά συνήθως δεν έχει σημασία στην ανάλυση δεδομένων.
Ένα άλλο σημαντικό μέλος της οικογένειας συναρτήσεων apply είναι η tapply() η οποία υπολογίζει μία ενιαία ομαδοποιημένη σύνοψη:
diamonds |>
group_by(cut) |>
summarize(price = mean(price))
#> # A tibble: 5 × 2
#> cut price
#> <ord> <dbl>
#> 1 Fair 4359.
#> 2 Good 3929.
#> 3 Very Good 3982.
#> 4 Premium 4584.
#> 5 Ideal 3458.
tapply(diamonds$price, diamonds$cut, mean)
#> Fair Good Very Good Premium Ideal
#> 4358.758 3928.864 3981.760 4584.258 3457.542Δυστυχώς, η tapply() επιστρέφει τα αποτελέσματά της σε ένα διάνυσμα με όνομα και απαιτεί κάποια προσπάθεια εάν θέλετε να συλλέξετε πολλές περιλήψεις και μεταβλητές ομαδοποίησης σε ένα πλαίσιο δεδομένων (είναι σίγουρα εφικτό το να μην το κάνετε αυτό και απλώς να εργαστείτε με ξεχωριστά διανύσματα, αλλά κατά την εμπειρία μας αυτό απλώς καθυστερεί την δουλειά που πρέπει να γίνει). Αν θέλετε να δείτε πώς μπορείτε να χρησιμοποιήσετε την tapply() ή άλλες βασικές τεχνικές για να εκτελέσετε άλλες ομαδοποιημένες περιλήψεις, ο Hadley έχει συγκεντρώσει μερικές τεχνικές σε ένα gist.
Το τελευταίο μέλος της οικογένειας apply είναι η apply(), η οποία λειτουργεί με μητρώα και arrays. Πιο αναλυτικά, προσέξτε την apply(df, 2, something), που είναι ένας αργός και δυνητικά επικίνδυνος τρόπος για να εφαρμόσετε την lapply(df, something). Αυτό σπάνια εμφανίζεται στην επιστήμη δεδομένων επειδή συνήθως εργαζόμαστε με πλαίσια δεδομένων και όχι με μητρώα.
27.5 Βρόγχοι for
Οι βρόγχοι for είναι το θεμελιώδες δομικό στοιχείο της επανάληψης που χρησιμοποιούν και οι οικογένειες apply και map στο παρασκήνιο Οι βρόγχοι for είναι ισχυρά και γενικά εργαλεία που είναι σημαντικό να μάθετε καθώς γίνεστε πιο έμπειρος προγραμματιστής στην R. Η βασική δομή ενός βρόγχου for μοιάζει με το εξής:
for (element in vector) {
# εφαρμόστε οτιδήποτε με την element
}Η πιο απλή χρήση των βρόγχων for είναι είναι για την επίτευξη του ίδιου αποτελέσματος με την walk(): η κλήση κάποιας συνάρτησης με κάποιο αποτέλεσμα σε κάθε στοιχείο μιας λίστας. Για παράδειγμα, στην Ενότητα 26.4.1 αντί να χρησιμοποιήσετε τη walk():
paths |> walk(append_file)Θα μπορούσαμε να χρησιμοποιήσουμε έναν βρόγχο for:
for (path in paths) {
append_file(path)
}Τα πράγματα γίνονται λίγο πιο δύσκολα αν θέλετε να αποθηκεύσετε την έξοδο του βρόγχου for, για παράδειγμα η ανάγνωση όλων των αρχείων excel σε έναν κατάλογο όπως κάναμε στο Κεφάλαιο 26:
paths <- dir("data/gapminder", pattern = "\\.xlsx$", full.names = TRUE)
files <- map(paths, readxl::read_excel)Υπάρχουν μερικές διαφορετικές τεχνικές που μπορείτε να χρησιμοποιήσετε, αλλά σας συνιστούμε να είστε ξεκάθαροι σχετικά με το πώς θα είναι το αποτέλεσμα εκ των προτέρων. Σε αυτήν την περίπτωση, θα θέλουμε μία λίστα με το ίδιο μήκος με το paths, την οποία μπορούμε να δημιουργήσουμε με την vector():
Στη συνέχεια, αντί να επαναλαμβάνουμε τις διαδικασίες μας στα στοιχεία του paths, θα τις επαναλαμβάνουμε στους δείκτες τους, χρησιμοποιώντας τη seq_along() για να δημιουργήσουμε ένα ευρετήριο για κάθε στοιχείο του paths:
seq_along(paths)
#> [1] 1 2 3 4 5 6 7 8 9 10 11 12Η χρήση των δεικτών είναι σημαντική γιατί μας επιτρέπει να συνδέσουμε κάθε θέση στην είσοδο με την αντίστοιχη θέση στην έξοδο:
for (i in seq_along(paths)) {
files[[i]] <- readxl::read_excel(paths[[i]])
}Για να συνδυάσετε τη λίστα των tibbles σε ένα μόνο tibble, μπορείτε να χρησιμοποιήσετε τις do.call() + rbind():
do.call(rbind, files)
#> # A tibble: 1,704 × 5
#> country continent lifeExp pop gdpPercap
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Afghanistan Asia 28.8 8425333 779.
#> 2 Albania Europe 55.2 1282697 1601.
#> 3 Algeria Africa 43.1 9279525 2449.
#> 4 Angola Africa 30.0 4232095 3521.
#> 5 Argentina Americas 62.5 17876956 5911.
#> 6 Australia Oceania 69.1 8691212 10040.
#> # ℹ 1,698 more rowsΑντί να δημιουργήσουμε μία λίστα και να αποθηκεύουμε εκεί τα αποτελέσματα καθώς προχωράμε, μία απλούστερη προσέγγιση είναι να δημιουργήσουμε το πλαίσιο δεδομένων κομμάτι-κομμάτι:
out <- NULL
for (path in paths) {
out <- rbind(out, readxl::read_excel(path))
}Συνιστούμε να αποφύγετε αυτό το μοτίβο γιατί μπορεί να γίνει αρκετά αργό όταν το διάνυσμα είναι πολύ μεγάλο. Αυτή είναι και η πηγή του μύθου ότι οι βρόγχοι for είναι αργοί: δεν είναι, αλλά το να αυξάνεται προοδευτικά ένα διάνυσμα, είναι.
27.6 Διαγράμματα
Πολλοί χρήστες της R, που δεν χρησιμοποιούν υπό άλλες συνθήκες το tidyverse, προτιμούν το πακέτο ggplot2 για σχεδίαση, λόγω των χρήσιμων χαρακτηριστικών της, όπως οι λογικές προεπιλογές, τα αυτοματοποιημένα υπομνήματα και η μοντέρνα εμφάνιση. Ωστόσο, οι βασικές συναρτήσεις σχεδίασης της R μπορούν να είναι ακόμα χρήσιμες μόνο και μόνο επειδή επειδή είναι τόσο συνοπτικές — χρειάζεται πολύ λίγη πληκτρολόγηση για να κάνετε ένα απλό εξερευνητικό διάγραμμα.
Υπάρχουν δύο κύριοι τύποι απλών διαγραμμάτων που θα δείτε εκεί έξω: διαγράμματα διασποράς και ιστογράμματα, που παράγονται με τις plot() και hist() αντίστοιχα. Ακολουθεί ένα γρήγορο παράδειγμα από το σύνολο δεδομένων diamonds:
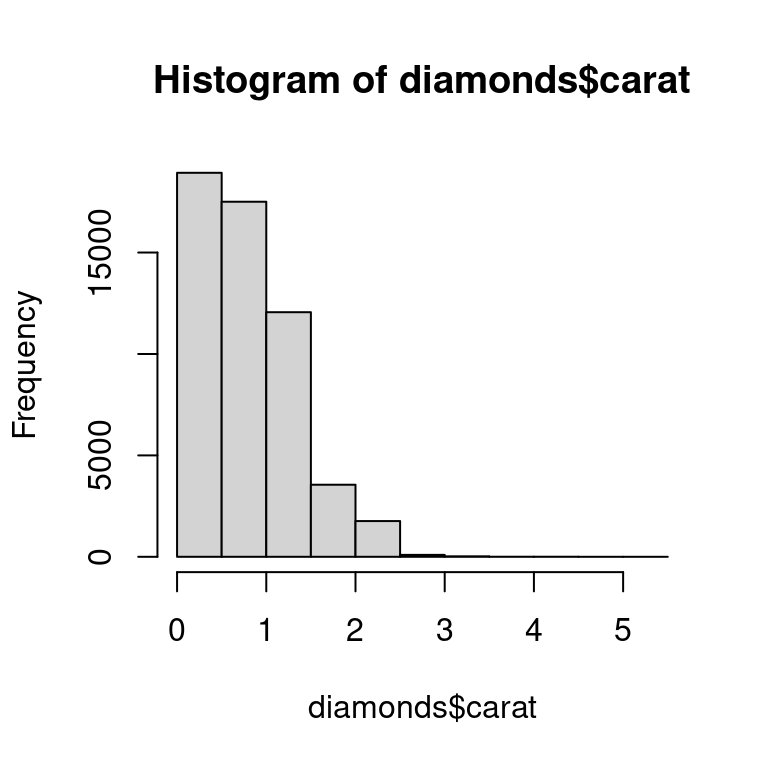
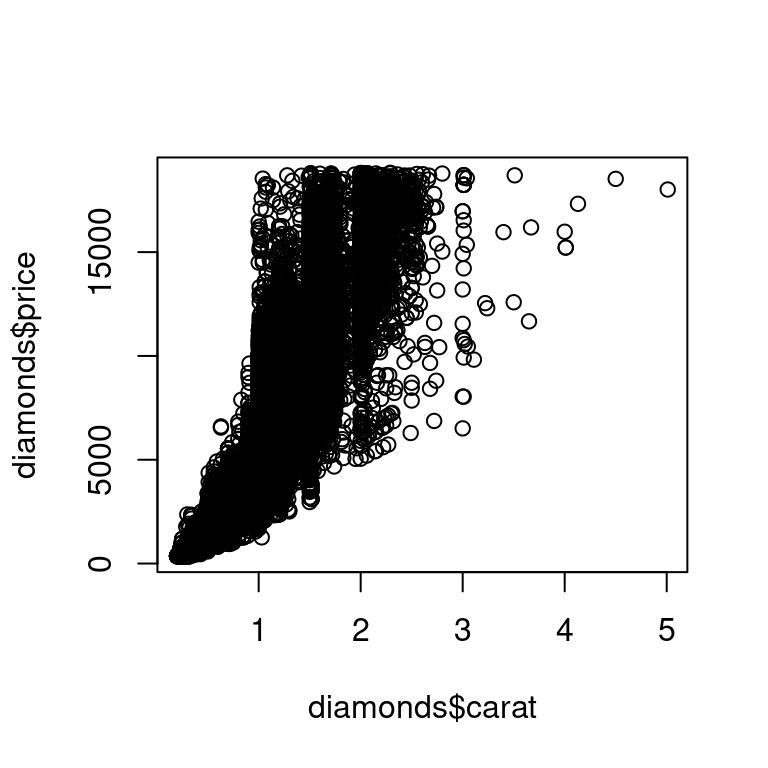
Σημειώστε ότι οι βασικές συναρτήσεις διαγραμμάτων λειτουργούν με διανύσματα, επομένως πρέπει να επιλέξετε στήλες από το πλαίσιο δεδομένων χρησιμοποιώντας το $ ή κάποια άλλη τεχνική.
27.7 Σύνοψη
Σε αυτό το κεφάλαιο, σας δείξαμε μία επιλογή από βασικές συναρτήσεις της R που είναι χρήσιμες για την δημιουργία υποσυνόλων και για την επανάληψη. Σε σύγκριση με προσεγγίσεις που συζητούνται αλλού στο βιβλίο, αυτές οι συναρτήσεις τείνουν να έχουν περισσότερο άρωμα “διανύσματος” παρά “πλαισίου δεδομένων”, επειδή οι βασικές συναρτήσεις της R τείνουν να λαμβάνουν μεμονωμένα διανύσματα ως είσοδο, παρά ένα πλαίσιο δεδομένων μαζί με προδιαγραφές στηλών. Αυτό συχνά, στον προγραμματισμό, κάνει τη ζωή πιο εύκολη και γι’ αυτό γίνεται πιο σημαντικό καθώς γράφετε περισσότερες συναρτήσεις και αρχίζετε να γράφετε τα δικά σας πακέτα.
Αυτό το κεφάλαιο ολοκληρώνει την ενότητα προγραμματισμού του βιβλίου. Έχετε κάνει μία καλή αρχή στο ταξίδι σας για να γίνετε όχι απλώς ένας επιστήμονας δεδομένων που χρησιμοποιεί την R, αλλά ένας επιστήμονας δεδομένων που μπορεί να προγραμματίσει σε R. Ελπίζουμε ότι αυτά τα κεφάλαια έχουν κεντρίσει το ενδιαφέρον σας για τον προγραμματισμό και ότι ανυπομονείτε να μάθετε περισσότερα εκτός αυτού του βιβλίου.
Διαβάστε το https://adv-r.hadley.nz/subsetting.html#subset-multiple για να δείτε πώς μπορείτε επίσης να ορίσετε ένα υποσύνολο σε ένα πλαίσιο δεδομένων σαν να είναι αντικείμενο μίας διάστασης και πώς μπορείτε να δημιουργήσετε ένα υποσύνολο με ένα μητρώο.↩︎
Ωστόσο, δεν χειρίζεται ομαδοποιημένα πλαίσια δεδομένων με διαφορετικό τρόπο και δεν υποστηρίζει βοηθητικές συναρτήσεις επιλογής όπως η
starts_with().↩︎Απλώς δεν διαθέτει βολικές λειτουργίες, όπως καταστάσεις προόδου και αναφορές για το ποιο στοιχείο προκάλεσε το πρόβλημα εάν υπάρχει σφάλμα.↩︎