12 Λογικά διανύσματα
12.1 Εισαγωγή
Σε αυτό το κεφάλαιο, θα μάθετε για εργαλεία που θα σας βοηθήσουν να δουλεύετε με λογικά διανύσματα. Τα λογικά διανύσματα είναι ο πιο απλός τύπος διανύσματος, επειδή κάθε στοιχείο μπορεί να είναι μόνο μία από τις τρεις πιθανές τιμές: TRUE, FALSE και NA. Είναι σχετικά σπάνιο να βρείτε λογικά διανύσματα στα ανεπεξέργαστα δεδομένα σας, αλλά θα τα δημιουργείτε και θα τα χειρίζεστε κατά τη διάρκεια σχεδόν κάθε ανάλυσης.
Θα ξεκινήσουμε συζητώντας τον πιο συνηθισμένο τρόπο δημιουργίας λογικών διανυσμάτων: τις αριθμητικές συγκρίσεις. Στη συνέχεια, θα μάθετε πώς μπορείτε να χρησιμοποιήσετε την άλγεβρα Boole για να συνδυάσετε διαφορετικά λογικά διανύσματα, καθώς και μερικές χρήσιμες συνόψεις. Θα ολοκληρώσουμε με τις if_else() και case_when(), δύο χρήσιμες συναρτήσεις για την υπο όρους πραγματοποίηση αλλαγών μέσα από λογικά διανύσματα.
12.1.1 Προαπαιτούμενα
Οι περισσότερες από τις λειτουργίες για τις οποίες θα μάθετε σε αυτό το κεφάλαιο παρέχονται από το βασικό πακέτο λειτουργιών της R, επομένως το tidyverse δεν χρειάζεται, αλλά θα το φορτώσουμε για να μπορούμε να χρησιμοποιήσουμε την mutate(), την filter(), και άλλες παρόμοιες συναρτήσεις σε πλαίσια δεδομένων. Θα συνεχίσουμε επίσης να αντλούμε παραδείγματα από το σύνολο δεδομένων nycflights13::flights.
Ωστόσο, καθώς αρχίζουμε να καλύπτουμε περισσότερα εργαλεία, δεν θα υπάρχει πάντα κάποιο αντίστοιχο τέλειο πραγματικό παράδειγμα. Θα αρχίσουμε λοιπόν φτιάχνοντας μερικά συνθετικά δεδομένα με την c():
x <- c(1, 2, 3, 5, 7, 11, 13)
x * 2
#> [1] 2 4 6 10 14 22 26Αυτό διευκολύνει την εξήγηση μεμονωμένων συναρτήσεων με το μειονέκτημα ότι είναι πιο δύσκολο να δούμε πώς αυτή μπορεί να εφαρμοστεί για τα προβλήματα των δεδομένων σας. Να θυμάστε ότι κάθε χειρισμό που εφαρμόζουμε σε ένα διάνυσμα, μπορείτε να τον εφαρμόσετε και σε μία μεταβλητή μέσα σε ένα πλαίσιο δεδομένων με την mutate() και άλλες παρόμοιες συναρτήσεις.
12.2 Συγκρίσεις
Ένας αρκετά συνηθισμένος τρόπος για να δημιουργήσετε ένα λογικό διάνυσμα είναι μέσω μιας αριθμητικής σύγκρισης με τους τελεστές <, <=, >, >=, != και ==. Μέχρι στιγμής, έχουμε δημιουργήσει ως επί το πλείστον λογικές μεταβλητές μέσα στην filter() — υπολογίζονται, χρησιμοποιούνται και στη συνέχεια αγνοούνται. Για παράδειγμα, η ακόλουθη filter βρίσκει όλες τις ημερήσιες αναχωρήσεις που φτάνουν περίπου στην ώρα τους:
flights |>
filter(dep_time > 600 & dep_time < 2000 & abs(arr_delay) < 20)
#> # A tibble: 172,286 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 601 600 1 844 850
#> 2 2013 1 1 602 610 -8 812 820
#> 3 2013 1 1 602 605 -3 821 805
#> 4 2013 1 1 606 610 -4 858 910
#> 5 2013 1 1 606 610 -4 837 845
#> 6 2013 1 1 607 607 0 858 915
#> # ℹ 172,280 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Είναι χρήσιμο να γνωρίζετε ότι αυτό είναι μία συντόμευση και ότι μπορείτε να δημιουργήσετε ξεχωριστά τις υποκείμενες λογικές μεταβλητές με την mutate():
flights |>
mutate(
daytime = dep_time > 600 & dep_time < 2000,
approx_ontime = abs(arr_delay) < 20,
.keep = "used"
)
#> # A tibble: 336,776 × 4
#> dep_time arr_delay daytime approx_ontime
#> <int> <dbl> <lgl> <lgl>
#> 1 517 11 FALSE TRUE
#> 2 533 20 FALSE FALSE
#> 3 542 33 FALSE FALSE
#> 4 544 -18 FALSE TRUE
#> 5 554 -25 FALSE FALSE
#> 6 554 12 FALSE TRUE
#> # ℹ 336,770 more rowsΑυτό είναι ιδιαίτερα χρήσιμο στην περίπτωση μιας πιο περίπλοκης λογικής, καθώς δίνοντας ονόματα στα ενδιάμεσα βήματα διευκολύνεται τόσο η ανάγνωση του κώδικά σας όσο και ο έλεγχος ότι κάθε βήμα έχει υπολογιστεί σωστά.
Εν τέλει, η αρχική filter είναι ισοδύναμη με:
12.2.1 Σύγκριση κινητής υποδιαστολής
Δώστε προσοχή στη χρήση του == με αριθμούς. Για παράδειγμα, φαίνεται ότι αυτό το διάνυσμα περιέχει τους αριθμούς 1 και 2:
Εάν όμως τα ελέγξετε για την ισότητά τους, θα πάρετε FALSE
x == c(1, 2)
#> [1] FALSE FALSEΤι συμβαίνει;
Οι υπολογιστές αποθηκεύουν αριθμούς με σταθερό αριθμό δεκαδικών ψηφίων, επομένως δεν υπάρχει τρόπος να αντιπροσωπεύσετε ακριβώς το 1/49 ή το sqrt(2) και οι επόμενοι υπολογισμοί θα είναι ελαφρώς ανόμοιοι. Μπορούμε να δούμε τις ακριβείς τιμές καλώντας την print() με το όρισμα digits1:
print(x, digits = 16)
#> [1] 0.9999999999999999 2.0000000000000004Μπορείτε να δείτε γιατί η R στρογγυλοποιεί από προεπιλογή αυτούς τους αριθμούς. Είναι πραγματικά πολύ κοντά σε αυτό που περιμένετε.
Τώρα που καταλάβατε γιατί το == αποτυγχάνει, τι μπορείτε να κάνετε για αυτό;
Μία επιλογή είναι να χρησιμοποιήσετε την dplyr::near() που αγνοεί μικρές διαφορές:
12.2.2 Κενές τιμές
Οι κενές τιμές αντιπροσωπεύουν το άγνωστο, επομένως είναι “μεταδοτικές”: σχεδόν οποιαδήποτε λειτουργία που περιλαμβάνει μία άγνωστη τιμή θα είναι επίσης άγνωστη:
NA > 5
#> [1] NA
10 == NA
#> [1] NAΤο αποτέλεσμα που προκαλεί περισσότερη σύγχυση είναι αυτό:
NA == NA
#> [1] NAΕίναι πιο εύκολο να καταλάβουμε γιατί ισχύει αυτό, εάν δώσουμε λίγες περισσότερες πληροφορίες:
# Δεν ξέρουμε την ηλικία της Mary
age_mary <- NA
# Δεν ξέρουμε την ηλικία του John
age_john <- NA
# Έχουν την ίδια ηλικία η Mary και ο John;
age_mary == age_john
#> [1] NA
# Δεν ξέρουμε!Επομένως, εάν θέλετε να βρείτε όλες τις πτήσεις όπου η dep_time έχει κενές τιμές, ο ακόλουθος κώδικας δεν λειτουργεί επειδή το dep_time == NA θα δώσει NA για κάθε γραμμή και μετά η filter() θα αφαιρέσει αυτόματα τις κενές τιμές:
flights |>
filter(dep_time == NA)
#> # A tibble: 0 × 19
#> # ℹ 19 variables: year <int>, month <int>, day <int>, dep_time <int>,
#> # sched_dep_time <int>, dep_delay <dbl>, arr_time <int>, …Aντ’ αυτού, θα χρειαστούμε ένα νέο εργαλείο: την is.na().
12.2.3 is.na()
H is.na(x) λειτουργεί με οποιονδήποτε τύπο διανύσματος και επιστρέφει TRUE για τιμές που λείπουν και FALSE για οτιδήποτε άλλο:
Μπορούμε να χρησιμοποιήσουμε την is.na() για να βρούμε όλες τις γραμμές με κενές τιμές στη dep_time:
flights |>
filter(is.na(dep_time))
#> # A tibble: 8,255 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 NA 1630 NA NA 1815
#> 2 2013 1 1 NA 1935 NA NA 2240
#> 3 2013 1 1 NA 1500 NA NA 1825
#> 4 2013 1 1 NA 600 NA NA 901
#> 5 2013 1 2 NA 1540 NA NA 1747
#> 6 2013 1 2 NA 1620 NA NA 1746
#> # ℹ 8,249 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Η is.na() μπορεί επίσης να είναι χρήσιμη στην arrange(). Η arrange() συνήθως βάζει όλες τις κενές τιμές στο τέλος, μπορείτε όμως να παρακάμψετε αυτήν την προεπιλογή ταξινομώντας πρώτα κατά is.na():
flights |>
filter(month == 1, day == 1) |>
arrange(dep_time)
#> # A tibble: 842 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 836 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …
flights |>
filter(month == 1, day == 1) |>
arrange(desc(is.na(dep_time)), dep_time)
#> # A tibble: 842 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 NA 1630 NA NA 1815
#> 2 2013 1 1 NA 1935 NA NA 2240
#> 3 2013 1 1 NA 1500 NA NA 1825
#> 4 2013 1 1 NA 600 NA NA 901
#> 5 2013 1 1 517 515 2 830 819
#> 6 2013 1 1 533 529 4 850 830
#> # ℹ 836 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Θα επανέλθουμε για να καλύψουμε τις κενές τιμές σε μεγαλύτερο βάθος στο Κεφάλαιο 18.
12.2.4 Ασκήσεις
- Πώς λειτουργεί η
dplyr::near(); Πληκτρολογήστεnearγια να δείτε τον πηγαίο κώδικα. Είναι το αποτέλεσμα τηςsqrt(2)^2κοντά στο 2; - Χρησιμοποιήστε τις
mutate(),is.na()καιcount()μαζί για να περιγράψετε πώς συνδέονται οι κενές τιμές στιςdep_time,sched_dep_timeκαιdep_delay.
12.3 Άλγεβρα Boole
Αφού έχετε πολλαπλά λογικά διανύσματα, μπορείτε να τα συνδυάσετε χρησιμοποιώντας άλγεβρα Boole. Στην R, το & είναι “και”, το | είναι “είτε”, το “!” είναι “όχι” και το xor() είναι αποκλειστική διάζευξη2. Για παράδειγμα, το df |> filter(!is.na(x)) βρίσκει όλες τις γραμμές όπου το x δεν είναι κενό και το df |> filter(x < -10 | x > 0) βρίσκει όλες τις γραμμές όπου το x είναι μικρότερο από -10 ή μεγαλύτερο από 0. Το Σχήμα 12.1 δείχνει το πλήρες σύνολο των λογικών πράξεων και τον τρόπο λειτουργίας τους.
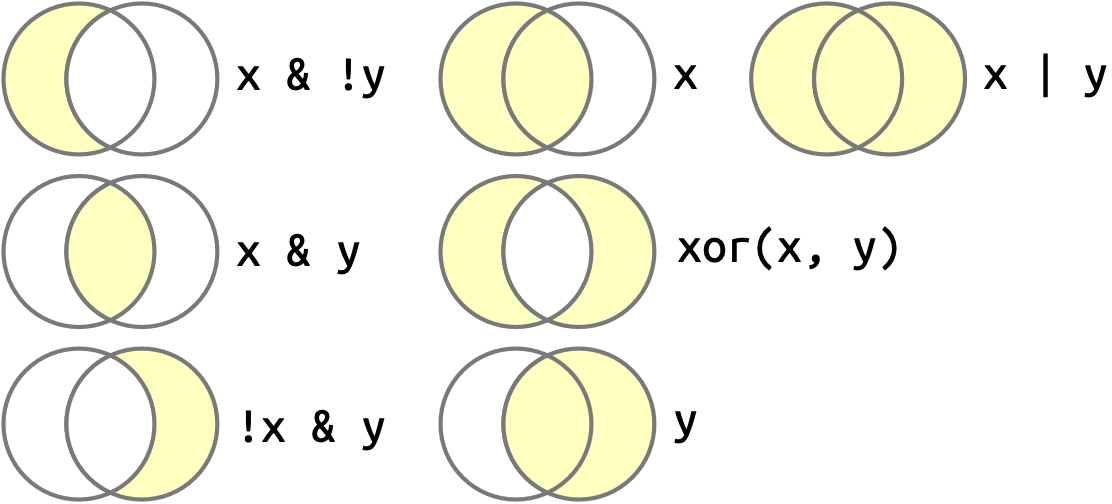
x είναι ο κύκλος στα αριστερά, το y είναι ο κύλος στα δεξιά, και η χρωματισμένη περιοχή δίχνει τα σημεία που επιλέγοντε απο κάθε τελεστή.
Εκτός από τα & και |, η R έχει επίσης τα && και ||. Μην τα χρησιμοποιείτε σε συναρτήσεις της dplyr! Ονομάζονται υπο συνθήκη τελεστές και επιστρέφουν μόνο ένα TRUE ή FALSE. Είναι σημαντικά για τον προγραμματισμό, όχι για την επιστήμη των δεδομένων.
12.3.1 Κενές τιμές
Οι κανόνες για τις κενές τιμές στην άλγεβρα Boole είναι λίγο δύσκολο να εξηγηθούν επειδή φαίνονται αντιφατικοί με μία πρώτη ματιά:
Για να καταλάβετε τι συμβαίνει, σκεφτείτε το NA | TRUE (NA είτε TRUE). Μία κενή τιμή σε ένα λογικό διάνυσμα σημαίνει ότι η τιμή μπορεί να είναι TRUE ή FALSE. Τα TRUE | TRUE και FALSE | TRUE είναι και τα δύο TRUE, επειδή τουλάχιστον ένα από αυτά είναι TRUE. Το NA | TRUE πρέπει επίσης να είναι TRUE επειδή το NA μπορεί να είναι είτε TRUE είτε FALSE. Ωστόσο, το NA | FALSE είναι NA, επειδή δεν γνωρίζουμε αν το NA είναι TRUE ή FALSE. Παρόμοια λογική ισχύει και για το NA & FALSE.
12.3.2 Σειρά πράξεων
Σημειώστε ότι η σειρά των πράξεων δεν λειτουργεί όπως στα ελληνικά. Δείτε τον παρακάτω κώδικα που βρίσκει όλες τις πτήσεις που αναχώρησαν τον Νοέμβριο ή τον Δεκέμβριο:
flights |>
filter(month == 11 | month == 12)Μπορεί να μπείτε στον πειρασμό να το γράψετε όπως θα λέγατε στα Ελληνικά: “Βρές όλες τις πτήσεις που αναχώρησαν τον Νοέμβριο ή τον Δεκέμβριο.”:
flights |>
filter(month == 11 | 12)
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 336,770 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Αυτός ο κώδικας δεν βγάζει κάποιο σφάλμα, αλλά επίσης δεν φαίνεται και να έχει δουλέψει. Τι συμβαίνει;
Εδώ, η R αξιολογεί πρώτα το month == 11 δημιουργώντας ένα λογικό διάνυσμα, το οποίο ονομάζουμε nov. Υπολογίζει, άρα, το nov | 12. Όταν χρησιμοποιείτε έναν αριθμό με έναν λογικό τελεστή, τα πάντα εκτός από το 0 μετατρέπονται σε TRUE, οπότε αυτό ισοδυναμεί με nov | TRUE που θα είναι πάντα TRUE, επομένως θα επιλεγούν όλες οι γραμμές:
flights |>
mutate(
nov = month == 11,
final = nov | 12,
.keep = "used"
)
#> # A tibble: 336,776 × 3
#> month nov final
#> <int> <lgl> <lgl>
#> 1 1 FALSE TRUE
#> 2 1 FALSE TRUE
#> 3 1 FALSE TRUE
#> 4 1 FALSE TRUE
#> 5 1 FALSE TRUE
#> 6 1 FALSE TRUE
#> # ℹ 336,770 more rows
12.3.3 %in%
Ένας εύκολος τρόπος για να αποφύγετε το πρόβλημα του να βάλετε στη σωστή σειρά τα == και | είναι να χρησιμοποιήσετε το %in%. Το x %in% y επιστρέφει ένα λογικό διάνυσμα ίδιου μήκους με το x που είναι TRUE κάθε φορά που μία τιμή στο x βρίσκεται οπουδήποτε στο y.
Για να βρούμε λοιπόν όλες τις πτήσεις τον Νοέμβριο και τον Δεκέμβριο θα μπορούσαμε να γράψουμε:
Σημειώστε ότι το %in% υπακούει σε διαφορετικούς κανόνες απο αυτούς του == για τα NA, καθώς το NA %in% NA είναι TRUE.
Το παραπάνω δημιουργεί μία χρήσιμη συντόμευση:
flights |>
filter(dep_time %in% c(NA, 0800))
#> # A tibble: 8,803 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 800 800 0 1022 1014
#> 2 2013 1 1 800 810 -10 949 955
#> 3 2013 1 1 NA 1630 NA NA 1815
#> 4 2013 1 1 NA 1935 NA NA 2240
#> 5 2013 1 1 NA 1500 NA NA 1825
#> 6 2013 1 1 NA 600 NA NA 901
#> # ℹ 8,797 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …12.3.4 Ασκήσεις
- Βρείτε όλες τις πτήσεις στις οποίες υπάρχουν κενές τιμές στην στήλη
arr_delayαλλά όχι στηνdep_delay. Βρείτε όλες τις πτήσεις στις οποίες δεν λείπουν τιμές ούτε στηνarr_time, ούτε στηνsched_arr_time, αλλά λείπουν στηνarr_delay. - Πόσες πτήσεις έχουν κενές τιμές στη στήλη
dep_time; Ποιες άλλες μεταβλητές έχουν κενές τιμές σε αυτές τις γραμμές; Τι μπορεί να αντιπροσωπεύουν αυτές οι γραμμές; - Αν υποθέσουμε ότι μία κενή τιμή στην στήλη
dep_timeσημαίνει ότι μία πτήση έχει ακυρωθεί, δείτε τον αριθμό των ακυρωμένων πτήσεων ανά ημέρα. Υπάρχει κάποιο μοτίβο; Υπάρχει σχέση μεταξύ του ποσοστού των ακυρωμένων πτήσεων και της μέσης καθυστέρησης των μη ακυρωμένων πτήσεων;
12.4 Συνόψεις
Οι ακόλουθες ενότητες περιγράφουν μερικές χρήσιμες τεχνικές για τη σύνοψη λογικών διανυσμάτων. Εκτός από συναρτήσεις που λειτουργούν ειδικά μόνο με λογικά διανύσματα, μπορείτε επίσης να χρησιμοποιήσετε συναρτήσεις που λειτουργούν με αριθμητικά διανύσματα.
12.4.1 Λογικές συνόψεις
Υπάρχουν δύο κύριες συναρτήσεις λογικών συνόψεων: η any() και η all(). Η any(x) είναι το ισοδύναμη του | και θα επιστρέψει TRUE εάν υπάρχουν τιμές TRUE στο x. Η all(x) ισοδυναμεί με το & και θα επιστρέψει TRUE μόνο εάν όλες οι τιμές του x είναι TRUE. Όπως και όλες οι συναρτήσεις σύνοψης, έτσι και αυτές θα επιστρέψουν NA εάν υπάρχουν κενές τιμές και, ως συνήθως, μπορείτε να τις αγνοήσετε με το na.rm = TRUE.
Για παράδειγμα, θα μπορούσαμε να χρησιμοποιήσουμε την all() και την any() για να μάθουμε εάν κάθε πτήση καθυστέρησε κατά την αναχώρηση κατά μία ώρα το πολύ, ή εάν κάποια πτήση είχε καθυστέρηση κατά την άφιξη κατά πέντε ώρες ή περισσότερο. Η χρήση της group_by() μας επιτρέπει να το κάνουμε αυτό και ανά ημέρα:
flights |>
group_by(year, month, day) |>
summarize(
all_delayed = all(dep_delay <= 60, na.rm = TRUE),
any_long_delay = any(arr_delay >= 300, na.rm = TRUE),
.groups = "drop"
)
#> # A tibble: 365 × 5
#> year month day all_delayed any_long_delay
#> <int> <int> <int> <lgl> <lgl>
#> 1 2013 1 1 FALSE TRUE
#> 2 2013 1 2 FALSE TRUE
#> 3 2013 1 3 FALSE FALSE
#> 4 2013 1 4 FALSE FALSE
#> 5 2013 1 5 FALSE TRUE
#> 6 2013 1 6 FALSE FALSE
#> # ℹ 359 more rowsΣτις περισσότερες περιπτώσεις, ωστόσο, η έξοδος της any() και της all() είναι λίγο απλή και θα ήταν καλό να μπορούσαμε να μάθουμε λίγες περισσότερες λεπτομέρειες σχετικά με το πόσες τιμές είναι TRUE ή FALSE. Αυτό μας οδηγεί στις αριθμητικές συνόψεις.
12.4.2 Αριθμητικές συνόψεις λογικών διανυσμάτων
Όταν χρησιμοποιείτε ένα λογικό διάνυσμα σε ένα αριθμητικό γενικό πλαίσιο, το TRUE γίνεται 1 και το FALSE γίνεται 0. Αυτό κάνει τις sum() και mean() πολύ χρήσιμες με λογικά διανύσματα, επειδή η sum(x) δίνει τον αριθμό των TRUE και η mean(x) δίνει την αναλογία των TRUE (γιατί η mean() διαιρείται απλώς με την sum()) με την length().
Αυτό, για παράδειγμα, μας επιτρέπει να δούμε το ποσοστό των πτήσεων που καθυστέρησαν κατά την αναχώρηση κατά μία ώρα το πολύ, αλλά και τον αριθμό των πτήσεων που καθυστέρησαν κατά την άφιξη κατά πέντε ώρες ή περισσότερο:
flights |>
group_by(year, month, day) |>
summarize(
proportion_delayed = mean(dep_delay <= 60, na.rm = TRUE),
count_long_delay = sum(arr_delay >= 300, na.rm = TRUE),
.groups = "drop"
)
#> # A tibble: 365 × 5
#> year month day proportion_delayed count_long_delay
#> <int> <int> <int> <dbl> <int>
#> 1 2013 1 1 0.939 3
#> 2 2013 1 2 0.914 3
#> 3 2013 1 3 0.941 0
#> 4 2013 1 4 0.953 0
#> 5 2013 1 5 0.964 1
#> 6 2013 1 6 0.959 0
#> # ℹ 359 more rows12.4.3 Λογική δημιουργία υποσυνόλων
Υπάρχει μία τελευταία χρήση για τα λογικά διανύσματα στις συνόψεις: μπορείτε να χρησιμοποιήσετε ένα λογικό διάνυσμα για να φιλτράρετε μία μεταβλητή σε ένα υποσύνολο. Αυτό χρησιμοποιεί τον βασικό τελεστή [ (ονομάζεται τελεστής υποσυνόλου), για τον οποίο θα μάθετε περισσότερα στην Ενότητα 27.2.
Φανταστείτε ότι θέλαμε να δούμε τη μέση καθυστέρηση μόνο για πτήσεις που είχαν όντως καθυστέρηση. Ένας τρόπος για να το κάνετε αυτό θα ήταν να φιλτράρετε πρώτα τις πτήσεις και στη συνέχεια να υπολογίσετε τη μέση καθυστέρηση:
flights |>
filter(arr_delay > 0) |>
group_by(year, month, day) |>
summarize(
behind = mean(arr_delay),
n = n(),
.groups = "drop"
)
#> # A tibble: 365 × 5
#> year month day behind n
#> <int> <int> <int> <dbl> <int>
#> 1 2013 1 1 32.5 461
#> 2 2013 1 2 32.0 535
#> 3 2013 1 3 27.7 460
#> 4 2013 1 4 28.3 297
#> 5 2013 1 5 22.6 238
#> 6 2013 1 6 24.4 381
#> # ℹ 359 more rowsΑυτό λειτουργεί, αλλά τι θα γινόταν αν θέλαμε να υπολογίσουμε και τη μέση καθυστέρηση για πτήσεις που έφτασαν νωρίς;
Θα πρέπει να εκτελέσουμε ένα ξεχωριστό βήμα φιλτραρίσματος και, στη συνέχεια, να καταλάβουμε πώς να συνδυάσουμε τα δύο πλαίσια δεδομένων μαζί3. Αντ’ αυτού, θα μπορούσατε να χρησιμοποιήσετε το [ για να εφαρμόσετε το φίλτρο: το arr_delay[arr_delay > 0] θα επιστρέψει μόνο τις θετικές καθυστερήσεις άφιξης.
Αυτό οδηγεί στο:
flights |>
group_by(year, month, day) |>
summarize(
behind = mean(arr_delay[arr_delay > 0], na.rm = TRUE),
ahead = mean(arr_delay[arr_delay < 0], na.rm = TRUE),
n = n(),
.groups = "drop"
)
#> # A tibble: 365 × 6
#> year month day behind ahead n
#> <int> <int> <int> <dbl> <dbl> <int>
#> 1 2013 1 1 32.5 -12.5 842
#> 2 2013 1 2 32.0 -14.3 943
#> 3 2013 1 3 27.7 -18.2 914
#> 4 2013 1 4 28.3 -17.0 915
#> 5 2013 1 5 22.6 -14.0 720
#> 6 2013 1 6 24.4 -13.6 832
#> # ℹ 359 more rowsΣημειώστε επίσης τη διαφορά στο μέγεθος των ομάδων: στο πρώτο κομμάτι κώδικα, η n() δίνει τον αριθμό των καθυστερημένων πτήσεων ανά ημέρα. Στο δεύτερο, η n() δίνει τον συνολικό αριθμό πτήσεων.
12.4.4 Ασκήσεις
- Τι θα κάνει η
sum(is.na(x));
Τι ηmean(is.na(x)); - Τι επιστρέφει η
prod()όταν εφαρμόζεται σε ένα λογικό διάνυσμα;
Με ποια συνάρτηση λογικής σύνοψης είναι ισοδύναμη;
Τι επιστρέφει ηmin()όταν εφαρμόζεται σε ένα λογικό διάνυσμα;
Με ποια συνάρτηση λογικής σύνοψης είναι ισοδύναμη;
Διαβάστε τις οδηγίες και εκτελέστε μερικά πειράματα.
12.5 Μετασχηματισμοί υπό όρους
Ένα από τα πιο ισχυρά χαρακτηριστικά των λογικών διανυσμάτων είναι η χρήση τους για μετασχηματισμούς υπό όρους, δηλαδή να κάνουν ένα πράγμα για τη συνθήκη x και κάτι διαφορετικό για τη συνθήκη y. Υπάρχουν δύο σημαντικά εργαλεία για αυτό: η if_else() και η case_when().
12.5.1 if_else()
Εάν θέλετε να χρησιμοποιήσετε μία τιμή όταν μία συνθήκη είναι TRUE και μία άλλη τιμή όταν είναι FALSE, μπορείτε να αξιοποιήσετε την dplyr::if_else()4. Τα τρία πρώτα όρισμα της if_else() χρησιμοποιούνται πάντα. Το πρώτο όρισμα, condition, είναι ένα λογικό διάνυσμα, το δεύτερο, true, δίνει την αντίστοιχη τιμή εξόδου όταν η συνθήκη είναι αληθής, και το τρίτο, false, δίνει την την αντίστοιχη τιμή εξόδου εάν η συνθήκη είναι ψευδής.
Ας ξεκινήσουμε με ένα απλό παράδειγμα χαρακτηρισμού ενός αριθμητικού διανύσματος είτε ως “+ve” (θετικό) ή “-ve” (αρνητικό):
Υπάρχει ένα προαιρετικό τέταρτο όρισμα, το missing, το οποίο θα χρησιμοποιηθεί εάν η είσοδος είναι NA:
if_else(x > 0, "+ve", "-ve", "???")
#> [1] "-ve" "-ve" "-ve" "-ve" "+ve" "+ve" "+ve" "???"Μπορείτε επίσης να χρησιμοποιήσετε διανύσματα για τα ορίσματα true και false. Για παράδειγμα, το παρακάτω μας επιτρέπει να δημιουργήσουμε μία συνοπτική υλοποίηση της abs():
if_else(x < 0, -x, x)
#> [1] 3 2 1 0 1 2 3 NAΜέχρι στιγμής όλα τα ορίσματα έχουν χρησιμοποιήσει τα ίδια διανύσματα. Μπορείτε όμως φυσικά να χρησιμοποιήσετε ο,τι επιθυμείτε. Για παράδειγμα, θα μπορούσατε να εφαρμόσετε μία απλή έκδοση της coalesce() ως εξής:
Ίσως έχετε παρατηρήσει μία μικρή ασάφεια στο παραπάνω παράδειγμα χαρακτηρισμού: το μηδέν δεν είναι ούτε θετικό ούτε αρνητικό. Θα μπορούσαμε να το επιλύσουμε προσθέτοντας μία επιπλέον if_else():
Αυτό είναι ήδη λίγο δύσκολο να διαβαστεί και μπορείτε να φανταστείτε ότι θα γίνει μόνο χειρότερο εάν έχετε περισσότερες συνθήκες. Αντ’ αυτού, μπορείτε να χρησιμοποιήσετε την dplyr::case_when().
12.5.2 case_when()
Η case_when() της dplyr είναι εμπνευσμένη από τη δήλωση CASE της SQL και παρέχει έναν ευέλικτο τρόπο εκτέλεσης διαφορετικών υπολογισμών για διαφορετικές συνθήκες. Έχει μία ειδική σύνταξη που δυστυχώς δεν μοιάζει με τίποτα άλλο που θα δείτε στο tidyverse. Χρειάζονται ζεύγη που μοιάζουν ως συνθήκη ~ έξοδος. Η συνθήκη πρέπει να είναι ένα λογικό διάνυσμα. Όταν είναι TRUE, η έξοδος θα χρησιμοποιηθεί.
Αυτό σημαίνει ότι θα μπορούσαμε να αναδημιουργήσουμε την προηγούμενη εμφωλευμένη if_else() ως εξής:
Είναι περισσότερος κώδικας, αλλά είναι επίσης πιο ξεκάθαρος.
Για να εξηγήσουμε πώς λειτουργεί η case_when(), ας εξερευνήσουμε μερικές πιο απλές περιπτώσεις. Εάν καμία από τις περιπτώσεις δεν ταιριάζει, η έξοδος παίρνει NA:
case_when(
x < 0 ~ "-ve",
x > 0 ~ "+ve"
)
#> [1] "-ve" "-ve" "-ve" NA "+ve" "+ve" "+ve" NAΧρησιμοποιήστε το .default εάν θέλετε να δημιουργήσετε μία τιμή για οποιαδήποτε άλλη περίπτωση (σαν προεπιλογή):
case_when(
x < 0 ~ "-ve",
x > 0 ~ "+ve",
.default = "???"
)
#> [1] "-ve" "-ve" "-ve" "???" "+ve" "+ve" "+ve" "???"Και σημειώστε ότι εάν πολλαπλές συνθήκες ταιριάζουν, θα χρησιμοποιηθεί μόνο η πρώτη:
case_when(
x > 0 ~ "+ve",
x > 2 ~ "big"
)
#> [1] NA NA NA NA "+ve" "+ve" "+ve" NAΑκριβώς όπως και με την if_else() μπορείτε να χρησιμοποιήσετε μεταβλητές και στις δύο πλευρές του ~ και μπορείτε να συνδυάσετε και να ταιριάξετε μεταβλητές όπως χρειάζεστε για το πρόβλημά σας. Για παράδειγμα, θα μπορούσαμε να χρησιμοποιήσουμε την case_when() για να παρέχουμε ορισμένους κατανοητούς χαρακτηρισμούς για την καθυστέρηση άφιξης:
flights |>
mutate(
status = case_when(
is.na(arr_delay) ~ "cancelled",
arr_delay < -30 ~ "very early",
arr_delay < -15 ~ "early",
abs(arr_delay) <= 15 ~ "on time",
arr_delay < 60 ~ "late",
arr_delay < Inf ~ "very late",
),
.keep = "used"
)
#> # A tibble: 336,776 × 2
#> arr_delay status
#> <dbl> <chr>
#> 1 11 on time
#> 2 20 late
#> 3 33 late
#> 4 -18 early
#> 5 -25 early
#> 6 12 on time
#> # ℹ 336,770 more rowsΝα είστε προσεκτικοί όταν γράφετε αυτού του είδους σύνθετες δηλώσεις case_when(). Οι δύο πρώτες μου απόπειρες χρησιμοποίησαν έναν συνδυασμό < και > και συνέχισα να δημιουργώ κατά λάθος αλληλεπικαλυπτόμενες συνθήκες.
12.5.3 Συμβατοί τύποι
Σημειώστε ότι τόσο η if_else() όσο και η case_when() απαιτούν συμβατούς τύπους τιμών στην έξοδο. Εάν δεν είναι συμβατοί, θα δείτε σφάλματα όπως αυτό:
Γενικά, σχετικά λίγοι τύποι είναι συμβατοί, επειδή η αυτόματη μετατροπή ενός τύπου διανύσματος σε άλλο είναι μία κοινή πηγή σφαλμάτων. Παρακάτω καταγράφονται οι πιο σημαντικές περιπτώσεις όπου οι τύποι είναι συμβατοί:
- Τα αριθμητικά και λογικά διανύσματα είναι συμβατά, όπως συζητήσαμε στην Ενότητα 12.4.2.
- Οι συμβολοσειρές και οι παράγοντες (Κεφάλαιο 16) είναι συμβατοί, επειδή μπορείτε να σκεφτείτε έναν παράγοντα ως μία συμβολοσειρά με ένα περιορισμένο σύνολο τιμών.
- Οι ημερομηνίες και οι ημερομηνίες με ώρα, τις οποίες θα συζητήσουμε στο Κεφάλαιο 17, είναι συμβατές επειδή μπορείτε να σκεφτείτε μία ημερομηνία ως μία ειδική περίπτωση ημερομηνίας-ώρας.
- Το
NA, το οποίο είναι τεχνικά ένα λογικό διάνυσμα, είναι συμβατό με τα πάντα επειδή κάθε διάνυσμα έχει κάποιο τρόπο να αναπαριστά μία κενή τιμή.
Δεν περιμένουμε από εσάς να απομνημονεύσετε αυτούς τους κανόνες, αλλά θα πρέπει με την πάροδο του χρόνου να τους συνηθίσετε, επειδή εφαρμόζονται με τον ίδιο τρόπο σε όλο το tidyverse.
12.5.4 Ασκήσεις
Ένας αριθμός είναι άρτιος εαν διαιρείται με το δύο, κάτι που στην R μπορείτε να το βρείτε με το
x %% 2 == 0. Χρησιμοποιήστε αυτό το γεγονός και τηνif_else()για να προσδιορίσετε εάν κάθε αριθμός μεταξύ 0 και 20 είναι άρτιος ή περιττός.Δεδομένου ενός διανύσματος ημερών όπως το
x <- c("Monday", "Saturday", "Wednesday"), χρησιμοποιήστε μία δήλωσηif_else()για να τις χαρακτηρίσετε ως Σαββατοκύριακα ή καθημερινές.Χρησιμοποιήστε την
if_else()για να υπολογίσετε την απόλυτη τιμή ενός αριθμητικού διανύσματος με όνομαx.Γράψτε μία δήλωση
case_when()που χρησιμοποιεί τις στήλεςmonthκαιdayαπό το σύνολο δεδομένωνflightsγια τον χαρακτηρισμό μιας επιλογής σημαντικών εορτών στις ΗΠΑ (π.χ. Πρωτοχρονιά, 4η Ιουλίου, Ημέρα των Ευχαριστιών και Χριστούγεννα). Δημιουργήστε πρώτα μία λογική στήλη που είναι είτεTRUEείτεFALSEκαι, στη συνέχεια, δημιουργήστε μία στήλη χαρακτήρων που είτε δίνει το όνομα της αργίας είτε είναιNA.
12.6 Σύνοψη
Ο ορισμός ενός λογικού διανύσματος είναι απλός γιατί κάθε τιμή πρέπει να είναι TRUE, FALSE ή NA. Παρ’ όλα αυτά, τα λογικά διανύσματα είναι αρκετά ισχυρά. Σε αυτό το κεφάλαιο, μάθατε πώς να δημιουργείτε λογικά διανύσματα με >, <, <=, >=, ==, !=, και is.na(), πώς για να τα συνδυάσετε με τα !, & και | και πώς να τα συνοψίσετε με τις any(), all(), sum() και mean(). Μάθατε επίσης τις ισχυρές συναρτήσεις if_else() και case_when() που σας επιτρέπουν να επιστρέφετε τιμές ανάλογα με την τιμή ενός λογικού διανύσματος.
Θα βλέπουμε λογικά διανύσματα αρκετές φορές στα επόμενα κεφάλαια. Για παράδειγμα, στο Κεφάλαιο 14 θα μάθετε για την str_detect(x, μοτίβο) η οποία επιστρέφει ένα λογικό διάνυσμα που είναι TRUE για τα στοιχεία του x που ταιριάζουν με το μοτίβο και στο Κεφάλαιο 17 θα δημιουργήσετε λογικά διανύσματα από τη σύγκριση ημερομηνιών και ωρών. Προς το παρόν όμως, θα προχωρήσουμε στον επόμενο πιο σημαντικό τύπο διανύσματος: τα αριθμητικά διανύσματα.
Η R συνήθως καλεί την print για εσάς (το
x, δηλαδή, είναι μία συντόμευση για τηνprint(x)), αλλά η κλήση της εκ νέου είναι χρήσιμη σε περιπτώσεις που θέλετε να παρέχετε άλλα ορίσματα.↩︎Δηλαδή, το
xor(x, y)είναι αληθές αν το x είναι αληθές ή το y είναι αληθές, αλλά όχι και τα δύο. Συνληθως, έτσι χρησιμοποιούμε το “είτε” στα Ελληνικά. Το «και τα δύο» δεν είναι συνήθως αποδεκτή απάντηση στην ερώτηση «θα ήθελες παγωτό ή κέικ;».↩︎Θα το καλύψουμε στο Κεφάλαιο 19.↩︎
Η
if_else()της dplyr είναι πολύ παρόμοιο με τηςifelse()του βασικού πακέτου λειτουργιών R. Υπάρχουν δύο βασικά πλεονεκτήματα τηςif_else()έναντι τηςifelse(): μπορείτε να επιλέξετε τι θα συμβεί με τις κενές τιμές και ηif_else()είναι πολύ πιο πιθανό να σας δώσει ένα σημαντικό σφάλμα εάν οι μεταβλητές σας έχουν μη συμβατούς τύπους.↩︎