24 Ιστοσυγκομιδή
24.1 Εισαγωγή
Αυτό το κεφάλαιο σας παρουσιάζει τα βασικά της ιστοσυγκομιδής (web scraping) με το πακέτο rvest. Η ιστοσυγκομιδή είναι ένα πολύ χρήσιμο εργαλείο για την εξαγωγή δεδομένων από ιστοσελίδες. Ορισμένοι ιστότοποι θα προσφέρουν την επιλογή ενός API, ένα σύνολο δομημένων αιτημάτων HTTP που επιστρέφουν δεδομένα ως JSON, τα οποία χειρίζεστε χρησιμοποιώντας τις τεχνικές από το Κεφάλαιο 23. Όπου είναι εφικτό, θα πρέπει να χρησιμοποιείτε το API1, γιατί συνήθως θα σας δώσει πιο αξιόπιστα δεδομένα. Δυστυχώς, όμως, ο προγραμματισμός με API είναι εκτός ύλης για αυτό το βιβλίο. Αντίθετα, διδάσκουμε την συγκομιδή (scraping), μία τεχνική που λειτουργεί είτε ένας ιστότοπος προσφέρει API είτε όχι.
Σε αυτό το κεφάλαιο, θα συζητήσουμε πρώτα το ηθικό κομμάτι και τη νομιμότητα της συγκομιδής προτού πάμε στα βασικά της HTML. Στη συνέχεια, θα μάθετε τα βασικά των επιλογέων CSS για τον εντοπισμό συγκεκριμένων στοιχείων στη σελίδα και τον τρόπο χρήσης των συναρτήσεων του rvest για τη λήψη δεδομένων από κείμενο και γνωρίσματα HTML στην R. Στη συνέχεια, θα συζητήσουμε ορισμένες τεχνικές για να καταλάβουμε ποιος επιλογέας CSS χρειάζεται για τη σελίδα που συγκομίζετε, προτού ολοκληρώσουμε με μερικές μελέτες περίπτωσης και μία σύντομη συζήτηση περί δυναμικών ιστοτόπων.
24.1.1 Προαπαιτούμενα
Σε αυτό το κεφάλαιο, θα επικεντρωθούμε στα εργαλεία που παρέχει το πακέτο rvest. Το rvest είναι μέλος του tidyverse, αλλά δεν είναι βασικό της μέλος, επομένως θα χρειαστεί να την φορτώσετε ξεχωριστά. Θα φορτώσουμε επίσης ολόκληρο το tidyverse, καθώς θα δούμε ότι είναι γενικά χρήσιμο όταν δουλεύουμε με τα δεδομένα που έχουμε συλλέξει.
24.2 Περί ηθικής και νομιμότητας της ιστοσυγκομιδής
Πριν ξεκινήσουμε να συζητάμε για τον κώδικα που θα χρειαστείτε για την ιστοσυγκομιδή, πρέπει να μιλήσουμε για το εάν είναι νόμιμο και ηθικό. Γενικά, η κατάσταση είναι περίπλοκη και για τα δύο.
Η νομιμότητα εξαρτάται αρκετά από το πού ζεις. Ωστόσο, ως γενική αρχή, εάν τα δεδομένα είναι δημοσίως διαθέσιμα, μη προσωπικά και πραγματολογικά, είναι πιθανό να είστε εντάξει2. Αυτοί οι τρεις παράγοντες είναι σημαντικοί επειδή συνδέονται με τους όρους και τις προϋποθέσεις, τις προσωπικές πληροφορίες και τα πνευματικά δικαιώματα του ιστότοπου, όπως θα συζητήσουμε παρακάτω.
Εάν τα δεδομένα δεν είναι δημόσια, μη προσωπικά ή τεκμηριωμένα ή εάν τα συλλέγετε ειδικά για κέρδος, θα πρέπει να μιλήσετε με έναν δικηγόρο. Σε κάθε περίπτωση, θα πρέπει να σέβεστε τους πόρους του διακομιστή που φιλοξενεί τις σελίδες που επιλέγετε για ιστοσυγκομιδή. Κυρίως, αυτό σημαίνει ότι εάν συγκομίζετε πολλαπλές σελίδες, θα πρέπει να φροντίσετε να περιμένετε για λίγο μεταξύ κάθε αιτήματος. Ένας εύκολος τρόπος για να το κάνετε αυτό είναι να χρησιμοποιήσετε το πακέτο polite του Dmytro Perepolkin. Θα κάνει μία παύση αυτόματα μεταξύ των αιτημάτων και θα αποθηκεύσει προσωρινά τα αποτελέσματα, ώστε να μην ζητήσετε ποτέ την ίδια σελίδα δύο φορές.
24.2.1 Όροι χρήσης
Αν κοιτάξετε προσεκτικά, θα διαπιστώσετε ότι πολλοί ιστότοποι περιλαμβάνουν έναν σύνδεσμο “όροι και προϋποθέσεις” ή “όροι παροχής υπηρεσιών” κάπου στη σελίδα και αν τον διαβάσετε προσεκτικά, συχνά θα ανακαλύψετε ότι ο ιστότοπος απαγορεύει ρητά την ιστοσυγκομιδή. Αυτές οι σελίδες τείνουν να περιέχουν αρκετά ευρείς νομικούς ισχυρισμούς έτσι ώστε οι εταιρίες να μπορούν να είναι καλυμμένες σε μεγαλύτερο εύρος. Είναι ευγενικό να σέβεστε αυτούς τους όρους παροχής υπηρεσιών όπου είναι δυνατόν, αλλά μην τους θεωρήσετε δεδομένους.
Τα δικαστήρια των ΗΠΑ έχουν γενικά διαπιστώσει ότι τοποθετώντας απλά τους όρους παροχής υπηρεσιών στο υποσέλιδο του ιστότοπου δεν αρκεί για να δεσμεύεστε από αυτούς, π.χ., HiQ Labs v. LinkedIn. Γενικά, για να δεσμευτείτε από τους όρους παροχής υπηρεσιών, πρέπει να έχετε κάνει κάποια ξεκάθαρη ενέργεια, όπως είναι η δημιουργία λογαριασμού ή η αποδοχή ενός πλαισίου με όρους. Αυτός είναι ο λόγος για τον οποίο έχει σημασία το εάν τα δεδομένα είναι δημόσια ή όχι. Εάν δεν χρειάζεστε λογαριασμό για να αποκτήσετε πρόσβαση σε αυτά, είναι απίθανο να δεσμεύεστε από τους όρους παροχής υπηρεσιών. Σημειώστε, ωστόσο, ότι η κατάσταση είναι μάλλον διαφορετική στην Ευρώπη, όπου τα δικαστήρια έχουν διαπιστώσει ότι οι όροι της υπηρεσίας ισχύουν ακόμη και αν δεν συμφωνείτε ρητά με αυτούς.
24.2.2 Δεδομένα προσωπικού χαρακτήρα
Ακόμα κι αν τα δεδομένα είναι δημόσια, θα πρέπει να είστε εξαιρετικά προσεκτικοί σχετικά με την συγκομιδή δεδομένων προσωπικού χαρακτήρα, όπως ονόματα, διευθύνσεις ηλεκτρονικού ταχυδρομείου, αριθμούς τηλεφώνου, ημερομηνίες γέννησης κ.λπ. Η Ευρώπη έχει ιδιαίτερα αυστηρούς νόμους σχετικά με τη συλλογή ή αποθήκευση τέτοιων δεδομένων (GDPR) και ανεξάρτητα από το πού ζείτε, είναι πιθανό να αντιμετωπίσετε ένα ηθικό αδιέξοδο. Για παράδειγμα, το 2016, μία ομάδα ερευνητών συγκόμισε πληροφορίες δημόσιων προφίλ χρήστη (π.χ. ονόματα χρήστη, ηλικία, φύλο, τοποθεσία κ.λπ.) περίπου 70.000 ατόμων από τον ιστότοπο γνωριμιών OkCupid και τα δημοσιοποίησαν χωρίς καμία προσπάθεια ανωνυμοποίησης. Ενώ οι ερευνητές θεώρησαν ότι δεν υπήρχε τίποτα λάθος με αυτό, καθώς τα δεδομένα ήταν ήδη δημόσια, αυτή η πράξη καταδικάστηκε ευρέως, λόγω ηθικών ανησυχιών σχετικά με την ταυτοποίηση των χρηστών των οποίων οι πληροφορίες δημοσιεύτηκαν στο σύνολο δεδομένων. Εάν η εργασία σας περιλαμβάνει συγκομιδή προσωπικών δεδομένων, συνιστούμε ανεπιφύλακτα να διαβάσετε για τη μελέτη της OkCupid3 καθώς και παρόμοιες μελέτες με αμφισβητήσιμη ερευνητική δεοντολογία, που αφορούν την απόκτηση και την δημοσιοποίηση δεδομένων προσωπικού χαρακτήρα.
24.2.3 Πνευματικά δικαιώματα
Τέλος, πρέπει επίσης να ανησυχείτε και για τη νομοθεσία περί πνευματικών δικαιωμάτων. Η νομοθεσία περί πνευματικών δικαιωμάτων είναι περίπλοκη, αλλά αξίζει να ρίξετε μία ματιά στον νόμο των ΗΠΑ που περιγράφει ακριβώς τι προστατεύεται: “[…] πρωτότυπα έργα παγιωμένα σε οποιοδήποτε απτό μέσο έκφρασης, […]”. Στη συνέχεια, περιγράφει συγκεκριμένες κατηγορίες που εφαρμόζεται, όπως λογοτεχνικά έργα, μουσικά έργα, κινηματογραφικές ταινίες και άλλα. Ιδιαίτερα, από την προστασία των πνευματικών δικαιωμάτων, απουσιάζουν τα δεδομένα. Αυτό σημαίνει ότι εφόσον περιορίζετε την συγκομιδή σας στα γεγονότα, δεν ισχύει η προστασία πνευματικών δικαιωμάτων. (Σημειώστε όμως ότι η Ευρώπη έχει ένα ξεχωριστό δικαίωμα “sui generis” που προστατεύει τις βάσεις δεδομένων.)
Για παράδειγμα, στις ΗΠΑ, οι συνταγές μαγειρικής δεν υπόκεινται σε πνευματικά δικαιώματα, επομένως τα πνευματικά δικαιώματα δεν μπορούν να χρησιμοποιηθούν για την προστασία τους. Αλλά αν αυτή η λίστα συνταγών συνοδεύεται από κάποιο σημαντικό καινοτόμο λογοτεχνικό περιεχόμενο, αυτό υπόκειται σε πνευματικά δικαιώματα. Αυτός είναι ο λόγος για τον οποίο όταν ψάχνετε για μία συνταγή στο διαδίκτυο, υπάρχει εκ των προτέρων πάντα τόσο πολύ περιεχόμενο.
Εάν χρειάζεται να συγκομίσετε πρωτογενές περιεχόμενο (όπως κείμενο ή εικόνες), ενδέχεται να προστατεύεστε σύμφωνα με το δόγμα της ορθής χρήσης. Ο κανόνας της δίκαιης χρήσης δεν είναι αυστηρός, αλλά σταθμίζει μία σειρά αρκετών παραγόντων. Είναι πιο πιθανό να ισχύει εάν συλλέγετε δεδομένα για ερευνητικούς ή μη εμπορικούς σκοπούς και εάν περιορίσετε την χρήση αυτού που συλλέγετε σε αυτό που χρειάζεστε.
24.3 Τα βασικά της HTML
Για να συγκομίσετε ιστοσελίδες, πρέπει πρώτα να κατανοήσετε λίγα πράγματα για την HTML, τη γλώσσα που περιγράφει τις ιστοσελίδες. Τα αρχικά της HTML σημαίνουν HyperText Markup Language και η σύνταξη μοιάζει κάπως έτσι:
<html>
<head>
<title>Page title</title>
</head>
<body>
<h1 id='first'>A heading</h1>
<p>Some text & <b>some bold text.</b></p>
<img src='myimg.png' width='100' height='100'>
</body>Η HTML έχει μία ιεραρχική δομή που σχηματίζεται από στοιχεία τα οποία αποτελούνται από μία ετικέτα έναρξης (π.χ. <tag>), προαιρετικά χαρακτηριστικά (id='first'), μία ετικέτα λήξης4 (όπως </tag>), και περιεχόμενα (οτιδήποτε μεταξύ της ετικέτας έναρξης και λήξης).
Εφόσον τα < και > χρησιμοποιούνται για τις ετικέτες έναρξης και λήξης, δεν μπορείτε να τις γράψετε απευθείας. Πρέπει να χρησιμοποιήσετε τις ακολουθίες διαφυγής της HTML > (μεγαλύτερο από) και < (λιγότερο από). Και δεδομένου ότι αυτές οι ακολουθίες διαφυγής χρησιμοποιούν το &, εάν θέλετε ένα κυριολεκτικό συμπλεκτικό σύμβολο θα πρέπει να το διαφύγετε ως &. Υπάρχει ένα ευρύ φάσμα πιθανών ακολουθιών διαφυγής στην HTML, αλλά δεν χρειάζεται να ανησυχείτε για αυτές καθώς το πακέτο rvest τις χειρίζεται αυτόματα για εσάς.
Η ιστοσυγκομιδή είναι εφικτή επειδή η δομή της πλειοψηφίας των σελίδων με δεδομένα που θέλετε να συγκομίσετε είναι συνεπής.
24.3.1 Στοιχεία
Υπάρχουν πάνω από 100 στοιχεία στην HTML. Μερικά από τα πιο σημαντικά είναι:
Κάθε σελίδα HTML πρέπει να περιέχει ένα στοιχείο
<html>και αυτό πρέπει να έχει δύο παιδιά: το<head>, που περιέχει μεταδεδομένα, όπως ο τίτλος της σελίδας, και το<body>, με το περιεχόμενο που βλέπετε στον browser.Ετικέτες στίξης όπως η
<h1>(επικεφαλίδα 1), η<section>(ενότητα), η<p>(παράγραφος) και η<ol>(διατεταγμένη λίστα) αποτελούν τη συνολική δομή της σελίδας.Ετικέτες μορφοποίησης όπως η
<b>(έντονη γραφή), η<i>(πλάγια γράμματα) και η<a>(σύνδεσμος) μορφοποιούν το κείμενο που υπάρχει μέσα σε ετικέτες στίξης.
Αν συναντήσετε μία ετικέτα που δεν έχετε ξαναδεί, μπορείτε να μάθετε τι κάνει με λίγο γκουγκλάρισμα. Ένα άλλο καλό μέρος για να ξεκινήσετε είναι το MDN Web Docs, το οποίο περιγράφει σχεδόν κάθε πτυχή του προγραμματισμού ιστοσελίδων.
Τα περισσότερα στοιχεία μπορούν να έχουν περιεχόμενο μεταξύ των ετικετών έναρξης και τέλους. Αυτό το περιεχόμενο μπορεί να είναι κείμενο ή περισσότερα στοιχεία. Για παράδειγμα, το ακόλουθο κομμάτι HTML περιέχει μία παράγραφο κειμένου, με μία λέξη με έντονη γραφή.
<p>
Hi! My <b>name</b> is Hadley.
</p>Τα παιδιά είναι τα στοιχεία που το στοιχείο <html> περιέχει, επομένως το στοιχείο <p> παραπάνω έχει ένα παιδί, το στοιχείο <b>. Το στοιχείο <b> δεν έχει παιδιά, αλλά έχει περιεχόμενα (το κείμενο “name”).
24.3.2 Χαρακτηριστικά
Οι ετικέτες μπορεί να έχουν ονοματισμένα χαρακτηριστικά που μοιάζουν ως name1='value1' name2='value2'. Δύο από τα πιο σημαντικά χαρακτηριστικά είναι το id και το class, που χρησιμοποιούνται σε συνδυασμό με την CSS (Cascading Style Sheets) για τον έλεγχο της οπτικής της σελίδας. Αυτά συνήθως είναι χρήσιμα κατά την συγκομιδή δεδομένων από μία σελίδα. Τα χαρακτηριστικά χρησιμοποιούνται επίσης για την καταγραφή του προορισμού των συνδέσμων (το χαρακτηριστικό href των στοιχείων <a>) και της πηγής των εικόνων (το χαρακτηριστικό src του στοιχείου <img>).
24.4 Εξάγοντας δεδομένα
Για να ξεκινήσετε την συγκομιδή, θα χρειαστείτε τη διεύθυνση URL της σελίδας που θέλετε, την οποία μπορείτε συνήθως να αντιγράψετε από τον browser. Στη συνέχεια, θα χρειαστεί να διαβάσετε τον HTML κώδικα για αυτήν τη σελίδα στην R με την read_html(). Αυτό επιστρέφει ένα αντικείμενο xml_document5 το οποίο στη συνέχεια θα χειριστείτε χρησιμοποιώντας συναρτήσεις του rvest:
html <- read_html("http://rvest.tidyverse.org/")
html
#> {html_document}
#> <html lang="en">
#> [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UT ...
#> [2] <body>\n <a href="#container" class="visually-hidden-focusable">Ski ...Το rvest περιλαμβάνει επίσης μία συνάρτηση που σας επιτρέπει να γράφετε HTML. Σε αυτό το κεφάλαιο, Θα χρησιμοποιήσουμε τη συνάρτηση αυτή όσο δείχνουμε πώς λειτουργούν οι διάφορες συναρτήσεις του rvest με απλά παραδείγματα.
html <- minimal_html("
<p>This is a paragraph</p>
<ul>
<li>This is a bulleted list</li>
</ul>
")
html
#> {html_document}
#> <html>
#> [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UT ...
#> [2] <body>\n<p>This is a paragraph</p>\n <ul>\n<li>This is a bulleted lis ...Τώρα που έχετε το HTML στην R, ήρθε η ώρα να εξάγετε τα δεδομένα που σας ενδιαφέρουν. Πρώτα θα μάθετε για τους επιλογείς CSS που σας επιτρέπουν να προσδιορίσετε τα στοιχεία που σας ενδιαφέρουν και τις συναρτήσεις του rvest που μπορείτε να χρησιμοποιήσετε για να εξάγετε δεδομένα από αυτά. Στη συνέχεια, θα καλύψουμε εν συντομία τους πίνακες στην HTML, οι οποίοι έχουν ορισμένα ειδικά εργαλεία.
24.4.1 Εντοπίζοντας στοιχεία
Το όνομα CSS είναι συντομογραφία για το cascading style sheets, και είναι ένα εργαλείο για τον ορισμό του οπτικού στυλ των εγγράφων HTML. Η CSS περιλαμβάνει μία μικρογραφία γλώσσας (συντακτικού) για την επιλογή στοιχείων από μία σελίδα και ονομάζεται επιλογείς CSS. Οι επιλογείς CSS ορίζουν μοτίβα για τον εντοπισμό στοιχείων HTML και είναι χρήσιμοι για την ιστοσυγκομιδή, καθώς παρέχουν έναν συνοπτικό τρόπο περιγραφής των στοιχείων που θέλετε να εξάγετε.
Θα επανέλθουμε στους επιλογείς CSS με περισσότερες λεπτομέρειες στην Ενότητα 24.5, αλλά ευτυχώς μπορείτε να καλύψετε αρκετό έδαφος μόνο με τρεις από αυτούς:
Ο επιλογέας
pεπιλέγει όλα τα στοιχεία<p>.Ο
.titleεπιλέγει όλα τα στοιχεία μεclass“title”.O
#titleεπιλέγει το στοιχείο με το χαρακτηριστικόidπου ισούται με “title”. Τα χαρακτηριστικά id πρέπει να είναι μοναδικά μέσα σε ένα έγγραφο, επομένως μόνο ένα στοιχείο θα επιλέγεται.
Ας δοκιμάσουμε αυτούς τους επιλογείς με ένα απλό παράδειγμα:
html <- minimal_html("
<h1>This is a heading</h1>
<p id='first'>This is a paragraph</p>
<p class='important'>This is an important paragraph</p>
")Χρησιμοποιήστε την html_elements() για να βρείτε όλα τα στοιχεία που ταιριάζουν με τον επιλογέα:
html |> html_elements("p")
#> {xml_nodeset (2)}
#> [1] <p id="first">This is a paragraph</p>
#> [2] <p class="important">This is an important paragraph</p>
html |> html_elements(".important")
#> {xml_nodeset (1)}
#> [1] <p class="important">This is an important paragraph</p>
html |> html_elements("#first")
#> {xml_nodeset (1)}
#> [1] <p id="first">This is a paragraph</p>Μία άλλη σημαντική συνάρτηση είναι η html_element(), η οποία επιστρέφει πάντα τον ίδιο αριθμό εξόδων με τις εισόδους. Εάν την εφαρμόσετε σε ολόκληρο το έγγραφο, θα σας δώσει την πρώτη, σε σειρά, αντιστοίχιση:
html |> html_element("p")
#> {html_node}
#> <p id="first">Υπάρχει μία σημαντική διαφορά μεταξύ της html_element() και της html_elements() όταν χρησιμοποιείτε έναν επιλογέα που δεν ταιριάζει με κανένα στοιχείο. Η html_elements() επιστρέφει ένα διάνυσμα μήκους 0, ενώ η html_element() επιστρέφει μία κενή τιμή. Αυτό θα γίνει σύντομα σημαντικό.
html |> html_elements("b")
#> {xml_nodeset (0)}
html |> html_element("b")
#> {xml_missing}
#> <NA>24.4.2 Ένθετες επιλογές
Στις περισσότερες περιπτώσεις, θα χρησιμοποιήσετε τις html_elements() και html_element() μαζί, χρησιμοποιώντας αρχικά την html_elements(), για να προσδιορίσετε στοιχεία που θα γίνουν παρατηρήσεις και στη συνέχεια την html_element(), για να βρείτε στοιχεία που θα γίνουν μεταβλητές. Ας το δούμε στην πράξη χρησιμοποιώντας ένα απλό παράδειγμα. Εδώ έχουμε μία μη ταξινομημένη λίστα (<ul>) όπου κάθε στοιχείο της λίστας (<li>) περιέχει πληροφορίες σχετικά με τέσσερις χαρακτήρες του StarWars:
html <- minimal_html("
<ul>
<li><b>C-3PO</b> is a <i>droid</i> that weighs <span class='weight'>167 kg</span></li>
<li><b>R4-P17</b> is a <i>droid</i></li>
<li><b>R2-D2</b> is a <i>droid</i> that weighs <span class='weight'>96 kg</span></li>
<li><b>Yoda</b> weighs <span class='weight'>66 kg</span></li>
</ul>
")Μπορούμε να χρησιμοποιήσουμε την html_elements() για να δημιουργήσουμε ένα διάνυσμα, όπου κάθε στοιχείο αντιστοιχεί σε διαφορετικό χαρακτήρα:
characters <- html |> html_elements("li")
characters
#> {xml_nodeset (4)}
#> [1] <li>\n<b>C-3PO</b> is a <i>droid</i> that weighs <span class="weight"> ...
#> [2] <li>\n<b>R4-P17</b> is a <i>droid</i>\n</li>
#> [3] <li>\n<b>R2-D2</b> is a <i>droid</i> that weighs <span class="weight"> ...
#> [4] <li>\n<b>Yoda</b> weighs <span class="weight">66 kg</span>\n</li>Για να εξαγάγουμε το όνομα κάθε χαρακτήρα, χρησιμοποιούμε την html_element(), γιατί όταν εφαρμοστεί στην έξοδο της html_elements() είναι σίγουρο ότι θα επιστρέψει ένα αποτέλεσμα ανά στοιχείο:
characters |> html_element("b")
#> {xml_nodeset (4)}
#> [1] <b>C-3PO</b>
#> [2] <b>R4-P17</b>
#> [3] <b>R2-D2</b>
#> [4] <b>Yoda</b>Η διάκριση μεταξύ html_element() και html_elements() δεν είναι σημαντική για το όνομα, αλλά είναι σημαντική για το βάρος. Θέλουμε να πάρουμε ένα βάρος για κάθε χαρακτήρα, ακόμα κι αν δεν υπάρχει <span> βάρος (weight). Αυτό κάνει η html_element():
characters |> html_element(".weight")
#> {xml_nodeset (4)}
#> [1] <span class="weight">167 kg</span>
#> [2] NA
#> [3] <span class="weight">96 kg</span>
#> [4] <span class="weight">66 kg</span>Η html_elements() βρίσκει όλα τα <span> βάρους (weight) που είναι παιδιά του characters. Υπάρχουν μόνο τρία από αυτά, οπότε χάνουμε τη σύνδεση μεταξύ ονομάτων και βαρών:
characters |> html_elements(".weight")
#> {xml_nodeset (3)}
#> [1] <span class="weight">167 kg</span>
#> [2] <span class="weight">96 kg</span>
#> [3] <span class="weight">66 kg</span>Τώρα που έχετε επιλέξει τα στοιχεία που σας ενδιαφέρουν, θα πρέπει να εξάγετε τα δεδομένα, είτε από τα περιεχόμενα του κειμένου είτε από ορισμένα χαρακτηριστικά.
24.4.3 Κείμενο και χαρακτηριστικά
Η html_text2()6 εξάγει τα περιεχόμενα απλού κειμένου ενός στοιχείου HTML:
characters |>
html_element("b") |>
html_text2()
#> [1] "C-3PO" "R4-P17" "R2-D2" "Yoda"
characters |>
html_element(".weight") |>
html_text2()
#> [1] "167 kg" NA "96 kg" "66 kg"Σημειώστε ότι τυχόν ακολουθίες διαφυγής θα αντιμετωπιστούν αυτόματα. θα δείτε ακολουθίες διαφυγής HTML μόνο στην πηγαίο κώδικα HTML, κι όχι στα δεδομένα που επιστρέφονται από το rvest.
Η html_attr() εξάγει δεδομένα από χαρακτηριστικά:
html <- minimal_html("
<p><a href='https://en.wikipedia.org/wiki/Cat'>cats</a></p>
<p><a href='https://en.wikipedia.org/wiki/Dog'>dogs</a></p>
")
html |>
html_elements("p") |>
html_element("a") |>
html_attr("href")
#> [1] "https://en.wikipedia.org/wiki/Cat" "https://en.wikipedia.org/wiki/Dog"Η html_attr() επιστρέφει πάντα μία συμβολοσειρά, επομένως εάν εξάγετε αριθμούς ή ημερομηνίες, θα πρέπει να εφαρμόσετε κάποια μετεπεξεργασία.
24.4.4 Πίνακες
Εάν είστε τυχεροί, τα δεδομένα σας θα είναι ήδη αποθηκευμένα σε έναν πίνακα HTML και θα πρέπει απλώς να τα διαβάσετε από αυτόν τον πίνακα. Συνήθως, είναι εύκολο να αναγνωρίσετε έναν πίνακα στον browser σας: θα έχει μία ορθογώνια δομή με γραμμές και στήλες και μπορείτε να τον αντιγράψετε και να τον επικολλήσετε σε ένα εργαλείο όπως το Excel.
Οι πίνακες HTML δημιουργούνται από τέσσερα κύρια στοιχεία: <table>, <tr> (γραμμή πίνακα), <th> (επικεφαλίδα πίνακα) και <td> (δεδομένα πίνακα). Ακολουθεί ένας απλός πίνακας HTML με δύο στήλες και τρεις γραμμές:
html <- minimal_html("
<table class='mytable'>
<tr><th>x</th> <th>y</th></tr>
<tr><td>1.5</td> <td>2.7</td></tr>
<tr><td>4.9</td> <td>1.3</td></tr>
<tr><td>7.2</td> <td>8.1</td></tr>
</table>
")Το πακέτο rvest παρέχει μία συνάρτηση που ξέρει πώς να διαβάζει αυτού του είδους δεδομένων: την html_table(). Αυτή επιστρέφει μία λίστα που περιέχει ένα tibble για κάθε πίνακα που βρίσκεται στη σελίδα. Χρησιμοποιήστε την html_element() για να προσδιορίσετε τον πίνακα που θέλετε να εξάγετε:
html |>
html_element(".mytable") |>
html_table()
#> # A tibble: 3 × 2
#> x y
#> <dbl> <dbl>
#> 1 1.5 2.7
#> 2 4.9 1.3
#> 3 7.2 8.1Σημειώστε ότι τα x και y έχουν μετατραπεί αυτόματα σε αριθμούς. Αυτή η αυτόματη μετατροπή δεν λειτουργεί πάντα, επομένως σε πιο σύνθετα σενάρια μπορεί να θέλετε να την απενεργοποιήσετε με το convert = FALSE και στη συνέχεια να κάνετε τη δική σας μετατροπή.
24.5 Εύρεση των κατάλληλων επιλογέων
Το να βρείτε τον επιλογέα που χρειάζεστε για τα δεδομένα σας είναι συνήθως το πιο δύσκολο μέρος του προβλήματος. Συχνά θα χρειαστεί να κάνετε κάποιους πειραματισμούς για να βρείτε έναν επιλογέα που είναι τόσο συγκεκριμένος (δηλαδή δεν επιλέγει πράγματα που δεν σας ενδιαφέρουν) όσο και ευαίσθητος (δηλαδή επιλέγει όλα όσα σας ενδιαφέρουν). Οι πολλαπλές δοκιμές είναι ένα φυσιολογικό κομμάτι της διαδικασίας! Υπάρχουν δύο βασικά εργαλεία που είναι διαθέσιμα για να σας βοηθήσουν με αυτήν τη διαδικασία: το SelectorGadget και τα εργαλεία προγραμματιστή του browser σας.
Το SelectorGadget είναι ένας σελιδοδείκτης javascript που δημιουργεί αυτόματα επιλογείς CSS με βάση τα θετικά και αρνητικά παραδείγματα που παρέχετε. Δεν λειτουργεί πάντα, αλλά όταν λειτουργεί, είναι μαγικό! Μπορείτε να μάθετε πώς να το εγκαταστήσετε και να το χρησιμοποιήσετε, είτε διαβάζοντας το https://rvest.tidyverse.org/articles/selectorgadget.html είτε παρακολουθώντας το βίντεο της Mine στη διεύθυνση https://www.youtube.com/watch?v=PetWV5g1Xsc.
Κάθε σύγχρονος browser συνοδεύεται από κάποια εργαλειοθήκη για προγραμματιστές, συνιστούμε όμως το Chrome, ακόμα κι αν δεν είναι το κανονικό σας πρόγραμμα περιήγησης: τα εργαλεία προγραμματιστή του είναι μερικά από τα καλύτερα και είναι άμεσα διαθέσιμα. Κάντε δεξί κλικ σε ένα στοιχείο στη σελίδα και κάντε κλικ στην επιλογή «Επιθεώρηση». Αυτό θα ανοίξει μία επεκτάσιμη προβολή της πλήρους σελίδας HTML, με κέντρο το στοιχείο στο οποίο μόλις κάνατε κλικ. Μπορείτε να το χρησιμοποιήσετε για να εξερευνήσετε τη σελίδα και να πάρετε μία ιδέα του ποιοι επιλογείς μπορεί να δουλέψουν. Δώστε ιδιαίτερη προσοχή στα χαρακτηριστικά κλάσης (class) και αναγνωριστικού (id), καθώς αυτά χρησιμοποιούνται συχνά για να σχηματίσουν την οπτική δομή της σελίδας, και ως εκ τούτου αποτελούν καλά εργαλεία για την εξαγωγή των δεδομένων που αναζητάτε.
Μέσα στην καρτέλα Στοιχεία, μπορείτε επίσης να κάνετε δεξί κλικ σε ένα στοιχείο και να επιλέξετε Αντιγραφή ως Eπιλογέα για να δημιουργήσετε έναν επιλογέα που θα προσδιορίζει μοναδικά το στοιχείο που σας ενδιαφέρει.
Εάν είτε το SelectorGadget είτε το Chrome DevTools έχουν δημιουργήσει έναν επιλογέα CSS που δεν καταλαβαίνετε, δοκιμάστε να δείτε το Selectors Explained που μεταφράζει τους επιλογείς CSS σε απλά αγγλικά. Εάν παρατηρείτε ότι το κάνετε αυτό συχνά, ίσως να θέλετε να μάθετε περισσότερα σχετικά με τους επιλογείς CSS γενικά. Συνιστούμε να ξεκινήσετε με το διασκεδαστικό εκπαιδευτικό υλικό CSS dinner, και στη συνέχεια να ανατρέξετε στο MDN web docs.
24.6 Βάζοντάς τα όλα μαζί
Ας τα συγκεντρώσουμε όλα αυτά μαζί για να συγκομίσουμε μερικούς ιστοτόπους. Υπάρχει ο κίνδυνος ότι αυτά τα παραδείγματα δεν θα λειτουργούν πλέον όταν τα εκτελέσετε — αυτή είναι η κύρια πρόκληση της ιστοσυγκομιδής. Εάν αλλάξει η δομή του ιστότοπου, τότε θα πρέπει να αλλάξετε και τον κώδικα.
24.6.1 StarWars
Το rvest περιλαμβάνει ένα πολύ απλό παράδειγμα στο vignette("starwars"). Αυτή είναι μία απλή σελίδα με ελάχιστη HTML, επομένως είναι ένα καλό μέρος για να ξεκινήσετε. Θα σας συνιστούσα να πλοηγηθείτε σε αυτήν τη σελίδα τώρα και να χρησιμοποιήσετε την “Επιθεώρηση στοιχείου” για να επιθεωρήσετε έναν από τους τίτλους που αναφέρεται σε μία ταινία Star Wars. Χρησιμοποιήστε το πληκτρολόγιο ή το ποντίκι για να εξερευνήσετε την ιεραρχία της HTML και να δείτε εάν μπορείτε να αποκτήσετε μία αίσθηση της κοινής δομής που χρησιμοποιείται από κάθε ταινία.
Θα πρέπει να μπορείτε να δείτε ότι κάθε ταινία έχει μία κοινή δομή που μοιάζει με αυτή:
<section>
<h2 data-id="1">The Phantom Menace</h2>
<p>Released: 1999-05-19</p>
<p>Director: <span class="director">George Lucas</span></p>
<div class="crawl">
<p>...</p>
<p>...</p>
<p>...</p>
</div>
</section>Στόχος μας είναι να μετατρέψουμε αυτά τα δεδομένα σε ένα πλαίσιο δεδομένων 7 γραμμών με μεταβλητές title, year, director, και intro. Θα ξεκινήσουμε διαβάζοντας το HTML αρχείο και εξάγοντας όλα τα στοιχεία <section>:
url <- "https://rvest.tidyverse.org/articles/starwars.html"
html <- read_html(url)
section <- html |> html_elements("section")
section
#> {xml_nodeset (7)}
#> [1] <section><h2 data-id="1">\nThe Phantom Menace\n</h2>\n<p>\nReleased: 1 ...
#> [2] <section><h2 data-id="2">\nAttack of the Clones\n</h2>\n<p>\nReleased: ...
#> [3] <section><h2 data-id="3">\nRevenge of the Sith\n</h2>\n<p>\nReleased: ...
#> [4] <section><h2 data-id="4">\nA New Hope\n</h2>\n<p>\nReleased: 1977-05-2 ...
#> [5] <section><h2 data-id="5">\nThe Empire Strikes Back\n</h2>\n<p>\nReleas ...
#> [6] <section><h2 data-id="6">\nReturn of the Jedi\n</h2>\n<p>\nReleased: 1 ...
#> [7] <section><h2 data-id="7">\nThe Force Awakens\n</h2>\n<p>\nReleased: 20 ...Αυτό ανακτά επτά στοιχεία που ταιριάζουν με τις επτά ταινίες που βρέθηκαν σε αυτήν τη σελίδα, υποδηλώνοντας ότι η χρήση του section ως επιλογέα είναι καλή. Η εξαγωγή των επιμέρους στοιχείων είναι απλή, καθώς τα δεδομένα βρίσκονται πάντα στο κείμενο. Το μόνο που χρειάζεται είναι να βρούμε τον κατάλληλο επιλογέα:
section |> html_element("h2") |> html_text2()
#> [1] "The Phantom Menace" "Attack of the Clones"
#> [3] "Revenge of the Sith" "A New Hope"
#> [5] "The Empire Strikes Back" "Return of the Jedi"
#> [7] "The Force Awakens"
section |> html_element(".director") |> html_text2()
#> [1] "George Lucas" "George Lucas" "George Lucas"
#> [4] "George Lucas" "Irvin Kershner" "Richard Marquand"
#> [7] "J. J. Abrams"Αφού το κάνουμε αυτό για κάθε στοιχείο, μπορούμε να βάλουμε όλα τα αποτελέσματα σε ένα tibble:
tibble(
title = section |>
html_element("h2") |>
html_text2(),
released = section |>
html_element("p") |>
html_text2() |>
str_remove("Released: ") |>
parse_date(),
director = section |>
html_element(".director") |>
html_text2(),
intro = section |>
html_element(".crawl") |>
html_text2()
)
#> # A tibble: 7 × 4
#> title released director intro
#> <chr> <date> <chr> <chr>
#> 1 The Phantom Menace 1999-05-19 George Lucas "Turmoil has engulfed …
#> 2 Attack of the Clones 2002-05-16 George Lucas "There is unrest in th…
#> 3 Revenge of the Sith 2005-05-19 George Lucas "War! The Republic is …
#> 4 A New Hope 1977-05-25 George Lucas "It is a period of civ…
#> 5 The Empire Strikes Back 1980-05-17 Irvin Kershner "It is a dark time for…
#> 6 Return of the Jedi 1983-05-25 Richard Marquand "Luke Skywalker has re…
#> # ℹ 1 more rowΕπεξεργαστήκαμε λίγο περισσότερο την released για να λάβουμε μία μεταβλητή που θα είναι εύκολη στη χρήση αργότερα για την ανάλυσή μας.
24.6.2 Κορυφαίες ταινίες στο IMDB
Για την επόμενη εργασία μας θα αντιμετωπίσουμε κάτι λίγο πιο δύσκολο, θα εξάγουμε τις κορυφαίες 250 ταινίες από το IMDb (Internet Movie Database). Την περίοδο που γράφτηκε η δεύτερη αγγλική έκδοση αυτού του κεφαλαίου, η σελίδα έμοιαζε έτσι Σχήμα 24.1.
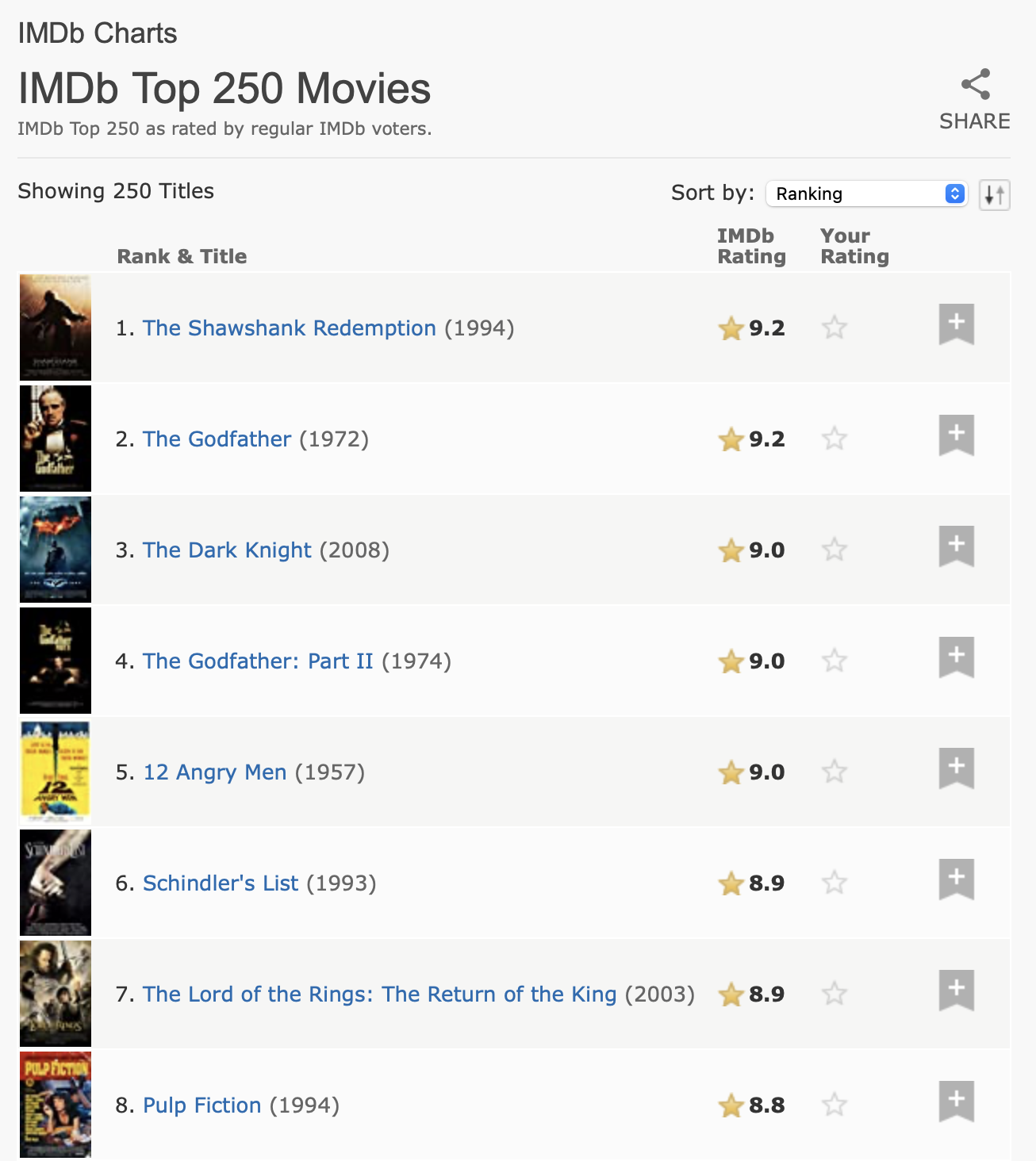
Τα δεδομένα αυτά έχουν μία σαφή δομή πίνακα, επομένως αξίζει να ξεκινήσετε με την html_table():
url <- "https://web.archive.org/web/20220201012049/https://www.imdb.com/chart/top/"
html <- read_html(url)
table <- html |>
html_element("table") |>
html_table()
table
#> # A tibble: 250 × 5
#> `` `Rank & Title` `IMDb Rating` `Your Rating` ``
#> <lgl> <chr> <dbl> <chr> <lgl>
#> 1 NA "1.\n The Shawshank Redempt… 9.2 "12345678910\n… NA
#> 2 NA "2.\n The Godfather\n … 9.1 "12345678910\n… NA
#> 3 NA "3.\n The Godfather: Part I… 9 "12345678910\n… NA
#> 4 NA "4.\n The Dark Knight\n … 9 "12345678910\n… NA
#> 5 NA "5.\n 12 Angry Men\n … 8.9 "12345678910\n… NA
#> 6 NA "6.\n Schindler's List\n … 8.9 "12345678910\n… NA
#> # ℹ 244 more rowsΤο παραπάνω περιλαμβάνει μερικές κενές στήλες, αλλά γενικά κάνει καλή δουλειά στην καταγραφή της πληροφορίας από τον πίνακα. Ωστόσο, πρέπει να το επεξεργαστούμε λίγο περισσότερο για να το κάνουμε πιο εύκολο στη χρήση. Αρχικά, θα μετονομάσουμε τις στήλες και θα αφαιρέσουμε το περιττό κενό διάστημα στην κατάταξη και τον τίτλο. Αυτό Θα το κάνουμε με την select() (αντί για την rename()), για να κάνουμε τη μετονομασία και την επιλογή μόνο αυτών των δύο στηλών σε ένα βήμα. Στη συνέχεια, θα αφαιρέσουμε τις νέες γραμμές και τα επιπλέον κενά και, στη συνέχεια, θα εφαρμόσουμε την separate_wider_regex() (από την Ενότητα 15.3.4) για να μεταφέρουμε τον τίτλο, το έτος και την κατάταξη στις δικές τους, ξεχωριστές μεταβλητές.
ratings <- table |>
select(
rank_title_year = `Rank & Title`,
rating = `IMDb Rating`
) |>
mutate(
rank_title_year = str_replace_all(rank_title_year, "\n +", " ")
) |>
separate_wider_regex(
rank_title_year,
patterns = c(
rank = "\\d+", "\\. ",
title = ".+", " +\\(",
year = "\\d+", "\\)"
)
)
ratings
#> # A tibble: 250 × 4
#> rank title year rating
#> <chr> <chr> <chr> <dbl>
#> 1 1 The Shawshank Redemption 1994 9.2
#> 2 2 The Godfather 1972 9.1
#> 3 3 The Godfather: Part II 1974 9
#> 4 4 The Dark Knight 2008 9
#> 5 5 12 Angry Men 1957 8.9
#> 6 6 Schindler's List 1993 8.9
#> # ℹ 244 more rowsΑκόμη και σε αυτήν την περίπτωση, όπου τα περισσότερα δεδομένα προέρχονται από κελιά πίνακα, αξίζει να κοιτάξετε τον ακατέργαστο κώδικα HTML. Εάν το κάνετε, θα ανακαλύψετε ότι μπορούμε να προσθέσουμε λίγα επιπλέον δεδομένα χρησιμοποιώντας ένα από τα χαρακτηριστικά. Αυτός είναι ένας από τους λόγους για τους οποίους αξίζει να αφιερώσετε λίγο χρόνο για να εξετάσετε την πηγαίο κώδικα της σελίδας. Μπορεί να βρείτε επιπλέον δεδομένα ή μία διαφορετική οδό για να πάρετε τα δεδομένα, η οποία να είναι ελαφρώς πιο εύκολη.
html |>
html_elements("td strong") |>
head() |>
html_attr("title")
#> [1] "9.2 based on 2,536,415 user ratings"
#> [2] "9.1 based on 1,745,675 user ratings"
#> [3] "9.0 based on 1,211,032 user ratings"
#> [4] "9.0 based on 2,486,931 user ratings"
#> [5] "8.9 based on 749,563 user ratings"
#> [6] "8.9 based on 1,295,705 user ratings"Αυτό, μπορούμε να το συνδυάσουμε με τα δεδομένα του πίνακα και να εφαρμόσουμε ξανά την separate_wider_regex() για να εξαγάγουμε το μέρος της πληροφορίας που μας ενδιαφέρει:
ratings |>
mutate(
rating_n = html |> html_elements("td strong") |> html_attr("title")
) |>
separate_wider_regex(
rating_n,
patterns = c(
"[0-9.]+ based on ",
number = "[0-9,]+",
" user ratings"
)
) |>
mutate(
number = parse_number(number)
)
#> # A tibble: 250 × 5
#> rank title year rating number
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 1 The Shawshank Redemption 1994 9.2 2536415
#> 2 2 The Godfather 1972 9.1 1745675
#> 3 3 The Godfather: Part II 1974 9 1211032
#> 4 4 The Dark Knight 2008 9 2486931
#> 5 5 12 Angry Men 1957 8.9 749563
#> 6 6 Schindler's List 1993 8.9 1295705
#> # ℹ 244 more rows24.7 Δυναμικές σελίδες
Μέχρι στιγμής έχουμε επικεντρωθεί σε ιστοτόπους όπου η html_elements() επιστρέφει ό,τι βλέπετε στον browser και συζητήσαμε πώς να τα αναλύσετε και πώς να τα οργανώσετε σε τακτοποιημένα πλαίσια δεδομένων. Κατά καιρούς, ωστόσο, θα βρείτε έναν ιστότοπο όπου η html_elements() και παρόμοιες συναρτήσεις δεν επιστρέφουν τίποτα σαν αυτό που βλέπετε στο πρόγραμμα περιήγησης. Σε πολλές περιπτώσεις, αυτό συμβαίνει επειδή προσπαθείτε να συγκομίσετε έναν ιστότοπο που δημιουργεί δυναμικά το περιεχόμενο της σελίδας με javascript. Αυτό δεν λειτουργεί προς το παρόν με το rvest, επειδή το πακέτο rvest κατεβάζει τον ακατέργαστο κώδικα HTML και δεν εκτελεί καθόλου javascript.
Είναι ακόμα εφικτό να συγκομίσετε αυτούς τους τύπους σελίδων, αλλά το πακέτο rvest πρέπει να χρησιμοποιήσει μία πιο δαπανηρή διαδικασία: την πλήρη προσομοίωση του browser, συμπεριλαμβανομένης της εκτέλεσης όλων των στοιχείων javascript. Η λειτουργία αυτή δεν ήταν διαθέσιμη τη στιγμή της σύνταξης αυτού του κειμένου, αλλά είναι κάτι πάνω στο οποίο εργαζόμαστε ενεργά και μπορεί να είναι διαθέσιμη κατά την περίοδο που θα διαβάζετε αυτό το βιβλίο. Χρησιμοποιεί το πακέτο chromote το οποίο εκτελεί στην πραγματικότητα τον browser Chrome στο παρασκήνιο και σας παρέχει πρόσθετα εργαλεία για να αλληλεπιδράσετε με τον ιστότοπο, όπως η πληκτρολόγηση κειμένου και το κλικ σε κουμπιά. Ρίξτε μία ματιά στον ιστότοπο του rvest για περισσότερες λεπτομέρειες.
24.8 Σύνοψη
Σε αυτό το κεφάλαιο, μάθατε το γιατί, το γιατί όχι, και το πώς της συγκομιδής δεδομένων από ιστοσελίδες. Πρώτα, μάθατε για τα βασικά της HTML και τη χρήση επιλογέων CSS για αναφορά σε συγκεκριμένα στοιχεία και μετά μάθατε να χρησιμοποιείτε το πακέτο rvest για να μεταφέρετε δεδομένα από την HTML στην R. Στη συνέχεια, παρουσιάσαμε την ιστοσυγκομιδή με δύο μελέτες περίπτωσης: ένα πιο απλό σενάριο για την συγκομιδή δεδομένων σχετικών με τις ταινίες StarWars από τον ιστότοπο του πακέτου rvest, και ένα πιο περίπλοκο σενάριο για την συγκομιδή των κορυφαίων 250 ταινιών από την IMDB.
Οι τεχνικές λεπτομέρειες της συγκομιδής δεδομένων από τον ιστό μπορεί να είναι περίπλοκες, ιδιαίτερα όταν ασχολούμαστε με ιστοτόπους, ωστόσο οι νομικές και ηθικές οπτικές μπορεί να είναι ακόμη πιο περίπλοκες. Είναι σημαντικό για εσάς να ενημερωθείτε και για τα δύο αυτά προτού ξεκινήσετε τη συγκομιδή δεδομένων.
Αυτό μας φέρνει στο τέλος της ενότητας του βιβλίου σχετικά με την εισαγωγή δεδομένων όπου έχετε μάθει τεχνικές για να λαμβάνετε δεδομένα από τον τόπο αποθήκευσής τους (υπολογιστικά φύλλα, βάσεις δεδομένων, αρχεία JSON και ιστοτόπους) σε μία τακτοποιημένη μορφή στην R. Τώρα ήρθε η ώρα να στρέψουμε το βλέμμα μας σε ένα νέο θέμα: πως να αξιοποιήσουμε στο έπακρο την R ως γλώσσα προγραμματισμού.
Πολλά δημοφιλή API έχουν ήδη αντίστοιχα πακέτα στο CRAN που τα ενθυλακώνουν, οπότε ξεκινήστε πρώτα με λίγη έρευνα!↩︎
Προφανώς δεν είμαστε δικηγόροι και αυτό δεν είναι νομική συμβουλή. Αυτή όμως είναι η καλύτερη περίληψη που μπορούμε να δώσουμε έχοντας διαβάσει αρκετά για αυτό το θέμα.↩︎
Ένα παράδειγμα άρθρου σχετικά με τη μελέτη της OkCupid δημοσιεύτηκε από το Wired, https://www.wired.com/2016/05/okcupid-study-reveals-perils-big-data-science .↩︎
Αυτή η κλάση προέρχεται από το πακέτο xml2. Το xml2 είναι ένα πακέτο χαμηλού επιπέδου στο οποίο το πακέτο rvest στηρίζεται.↩︎
Αυτή η κλάση προέρχεται από το πακέτο xml2. Το xml2 είναι ένα πακέτο χαμηλού επιπέδου στο οποίο το πακέτο rvest στηρίζεται.↩︎
Η rvest παρέχει επίσης την
html_text(), αλλά θα πρέπει σχεδόν πάντα να χρησιμοποιείτε τηνhtml_text2(), καθώς κάνει καλύτερη δουλειά στη μετατροπή του ένθετου HTML κώδικα σε κείμενο.↩︎