Εισαγωγή
Η επιστήμη των δεδομένων είναι ένας συναρπαστικός κλάδος που σας επιτρέπει να μετατρέψετε τα ακατέργαστα δεδομένα σε πληροφορία και γνώση. Ο στόχος του βιβλίου “Η R για την Επιστήμη των Δεδομένων” είναι να σας βοηθήσει να μάθετε τα πιο σημαντικά εργαλεία σε R που θα σας επιτρέψουν να εφαρμόσετε την επιστήμη των δεδομένων αποτελεσματικά και αναπαράξιμα καθώς διασκεδάζετε στην πορεία 😃. Έχοντας διαβάσει αυτό το βιβλίο, θα έχετε τα εργαλεία για να αντιμετωπίσετε ένα μεγάλο εύρος προκλήσεων της επιστήμης των δεδομένων χρησιμοποιώντας τα καλύτερα μέρη της R.
Τι θα μάθετε
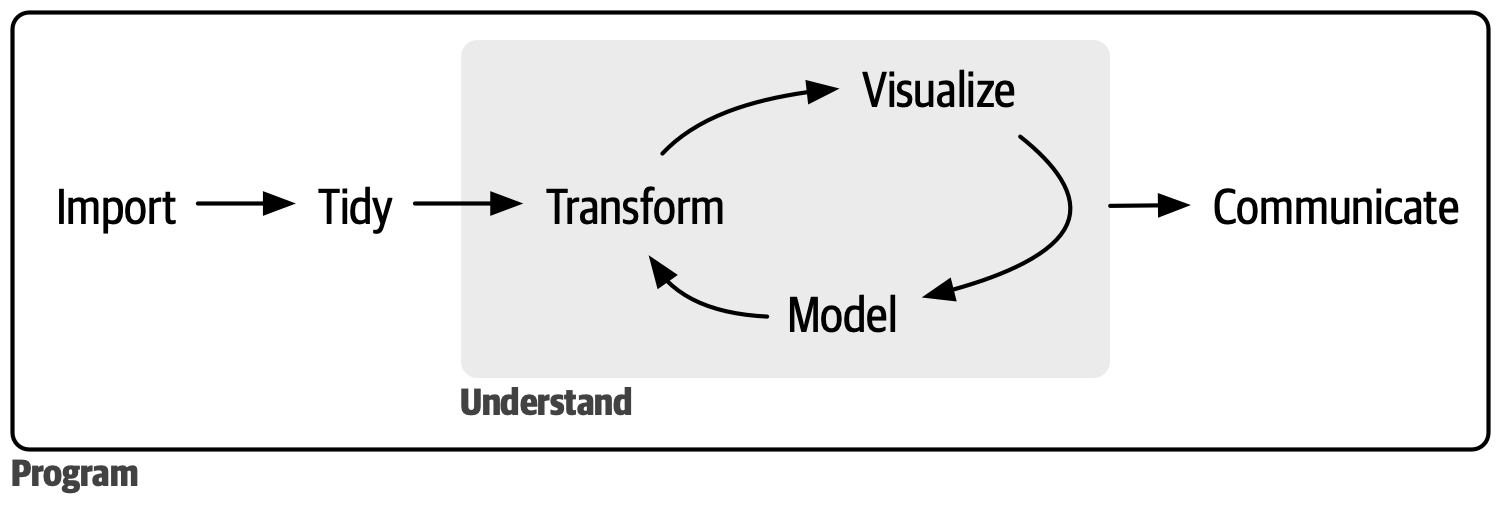
Η επιστήμη των δεδομένων είναι πεδίο με μεγάλο εύρος και είναι αδύνατο να κατανοηθούν τα πάντα διαβάζοντας ένα μόνο βιβλίο. Αυτό το βιβλίο στοχεύει στο να σας δώσει μία σταθερή βάση στα πιο σημαντικά εργαλεία και αρκετή γνώση έτσι ώστε να βρείτε τους πόρους για να μάθετε περισσότερα όταν αυτό χρειαστεί. Το μοντέλο μας σχετικά με τα βήματα ενός τυπικού έργου επιστήμης δεδομένων μοιάζει κάπως έτσι Σχήμα 1.
Πρώτα, πρέπει να εισάγετε τα δεδομένα σας στην R. Αυτό συνήθως σημαίνει ότι λαμβάνετε δεδομένα που είναι αποθηκευμένα σε ένα αρχείο, βάση δεδομένων ή διεπαφή προγραμματισμού εφαρμογών (application programming interface; API) και τα φορτώνετε σε ένα πλαίσιο δεδομένων στην R. Εάν δεν μπορείτε να βάλετε τα δεδομένα σας στην R, δεν μπορείτε να κάνετε επιστήμη δεδομένων σε αυτά!
Αφού εισάγετε τα δεδομένα σας, είναι καλή ιδέα να τα οργανώσετε. Η οργάνωση των δεδομένων σας σημαίνει την αποθήκευσή τους σε μία συνεπή μορφή που ταιριάζει με τη σημασιολογία του συνόλου δεδομένων ως προς τον αρχικό τρόπο αποθήκευσής τους. Εν συντομία, όταν τα δεδομένα σας είναι οργανωμένα, κάθε στήλη είναι μία μεταβλητή και κάθε γραμμή είναι μία παρατήρηση. Τα οργανωμένα δεδομένα είναι σημαντικά επειδή η συνέπεια στη δομή τους σας επιτρέπει να εστιάσετε στην απάντηση ερωτήσεων σχετικά με τα δεδομένα και όχι στο να αγωνίζεστε να φέρετε τα δεδομένα στη σωστή μορφή για διαφορετικές λειτουργίες.
Αφού έχετε οργανωμένα δεδομένα, ένα σύνηθες επόμενο βήμα είναι να τα μετασχηματίσετε. Ο μετασχηματισμός περιλαμβάνει τον περιορισμό των παρατηρήσεων (όπως για παράδειγμα όλοι οι άνθρωποι σε μία συγκεκριμένη πόλη ή όλα τα δεδομένα του περασμένου έτους), τη δημιουργία νέων μεταβλητών που είναι συναρτήσεις άλλων (όπως ο εξ αποστάσεων υπολογισμός της ταχύτητας και του χρόνου) και τον υπολογισμό ενός συνόλου συνοπτικών στατιστικών (όπως αθροίσματα και μέσοι όροι). Όλα μαζί, η οργάνωση και ο μετασχηματισμός ονομάζονται διένεξη (wrangling) επειδή η μετατροπή των δεδομένων σε μία εύκολα επεξεργάσιμη μορφή συχνά μοιάζει με πάλη!
Έχοντας οργανωμένα δεδομένα με τις μεταβλητές που χρειάζεστε, υπάρχουν δύο κύριες μηχανές παραγωγής γνώσης: οπτικοποίηση και μοντελοποίηση. Αυτά έχουν συμπληρωματικά πλεονεκτήματα και αδυναμίες, επομένως τα στοιχεία οποιασδήποτε σωστής ανάλυσης δεδομένων θα εναλλάσσονται μεταξύ των δύο πολλές φορές.
Η οπτικοποίηση είναι μία βασικά ανθρώπινη δραστηριότητα. Μία καλή οπτικοποίηση θα σας δείξει στοιχεία που δεν περιμένατε ή θα δημιουργήσει νέες ερωτήσεις σχετικά με τα δεδομένα. Μία καλή οπτικοποίηση μπορεί επίσης να υποδηλώσει ότι ρωτάτε μία λάθος ερώτηση ή ότι πρέπει να συλλέξετε διαφορετικά δεδομένα. Οι οπτικοποιήσεις μπορεί να σας εκπλήξουν, αλλά η χρήση τους δεν επεκτείνεται ιδιαίτερα διότι απαιτούν ανθρώπινη ερμηνεία.
Τα μοντέλα είναι συμπληρωματικά εργαλεία οπτικοποίησης. Αφού κάνετε τις ερωτήσεις σας αρκετά ακριβείς, μπορείτε να χρησιμοποιήσετε ένα μοντέλο για να τις απαντήσετε. Τα μοντέλα είναι βασικά μαθηματικά ή υπολογιστικά εργαλεία, επομένως επεκτείνονται συνήθως καλά. Ακόμα κι όταν δεν το κάνουν, συνήθως είναι φθηνότερο να αγοράσεις περισσότερους υπολογιστές παρά περισσότερους εγκεφάλους! Όμως, κάθε μοντέλο κάνει υποθέσεις, και από τη φύση του, ένα μοντέλο δεν μπορεί να αμφισβητήσει τις δικές του υποθέσεις. Αυτό σημαίνει ότι ένα μοντέλο δεν μπορεί κατα βάση να σας εκπλήξει.
Το τελευταίο βήμα της επιστήμης δεδομένων είναι η επικοινωνία, ένα απολύτως κρίσιμο μέρος κάθε έργου ανάλυσης δεδομένων. Δεν έχει σημασία πόσο καλά τα μοντέλα και η οπτικοποίηση σας οδήγησαν να κατανοήσετε τα δεδομένα εάν δεν μπορείτε επίσης να κοινοποιήσετε τα αποτελέσματά σας σε άλλους.
Γύρω από όλα αυτά τα εργαλεία είναι ο προγραμματισμός. Ο προγραμματισμός είναι ένα γενικό εργαλείο που χρησιμοποιείτε σχεδόν σε κάθε μέρος ενός έργου επιστήμης δεδομένων. Δεν χρειάζεται να είστε έμπειρος προγραμματιστής για να είστε επιτυχημένος επιστήμονας δεδομένων, αλλά το να μάθετε περισσότερα για τον προγραμματισμό αποδίδει, επειδή το να γίνετε καλύτερος προγραμματιστής σας επιτρέπει να αυτοματοποιείτε συνηθισμένες εργασίες και να επιλύετε νέα προβλήματα με μεγαλύτερη ευκολία.
Θα χρησιμοποιήσετε αυτά τα εργαλεία σε κάθε έργο επιστήμης δεδομένων, αλλά για τα περισσότερα έργα, δεν είναι αρκετά. Υπάρχει ένας πρόχειρος “80/20” κανόνας που ισχύει εδώ: μπορείτε να αντιμετωπίσετε περίπου το 80% κάθε έργου χρησιμοποιώντας τα εργαλεία που θα μάθετε σε αυτό το βιβλίο, αλλά θα χρειαστείτε άλλα εργαλεία για να αντιμετωπίσετε το υπόλοιπο 20%. Σε όλα τα μέρη του βιβλίου αυτού, θα σας υποδεικνύουμε πηγές μέσα από τις οποίες μπορείτε να μάθετε περισσότερα.
Πώς είναι οργανωμένο αυτό το βιβλίο
Η προηγούμενη περιγραφή των εργαλείων της επιστήμης των δεδομένων είναι οργανωμένη κατά προσέγγιση σύμφωνα με τη σειρά με την οποία τα χρησιμοποιείτε σε μία ανάλυση (αν και, φυσικά, θα τα επαναλάβετε αρκετές φορές). Σύμφωνα με την εμπειρία μας, ωστόσο, η εκμάθηση της εισαγωγής και οργάνωσης δεδομένων ως πρώτο βήμα δεν είναι η ιδανική, επειδή, στο 80% των περιπτώσεων, γίνεται ρουτίνα και βαρετή, και το υπόλοιπο 20% των περιπτώσεων είναι περίεργη και κουραστική. Αυτό είναι ένα κακό μέρος για να ξεκινήσετε να μάθετε ένα νέο αντικείμενο! Αντίθετα, θα ξεκινήσουμε με την οπτικοποίηση και τον μετασχηματισμό δεδομένων που έχουν ήδη εισαχθεί και οργανωθεί. Έτσι, όταν εισάγετε και οργανώνετε τα δικά σας δεδομένα, το κίνητρό σας θα παραμείνει υψηλό επειδή γνωρίζετε ότι η ταλαιπωρία αξίζει τον κόπο.
Μέσα σε κάθε κεφάλαιο, προσπαθούμε να τηρούμε ένα συνεπές μοτίβο: ξεκινάμε με μερικά ενθαρρυντικά παραδείγματα, ώστε να μπορείτε να δείτε τη μεγαλύτερη εικόνα και στη συνέχεια εξερευνούμε τις λεπτομέρειες. Κάθε ενότητα του βιβλίου συνδυάζεται με ασκήσεις που θα σας βοηθήσουν να εξασκήσετε αυτά που έχετε μάθει. Αν και μπορεί να είναι δελεαστικό να παραλείψετε τις ασκήσεις, δεν υπάρχει καλύτερος τρόπος για να μάθετε από την εξάσκηση πάνω σε πραγματικά προβλήματα.
Τι δεν θα μάθετε
Υπάρχουν πολλά σημαντικά θέματα που δεν καλύπτει αυτό το βιβλίο. Πιστεύουμε ότι είναι σημαντικό να παραμείνετε αδίστακτα συγκεντρωμένοι στα βασικά, ώστε να μπορείτε να είστε έτοιμοι όσο το δυνατόν γρηγορότερα. Αυτό σημαίνει ότι αυτό το βιβλίο δεν μπορεί να καλύψει κάθε σημαντικό θέμα.
Μοντελοποίηση
Η μοντελοποίηση είναι εξαιρετικά σημαντική για την επιστήμη των δεδομένων, αλλά είναι ένα μεγάλο θέμα και, δυστυχώς, απλώς δεν έχουμε τον χώρο να της δώσουμε την κάλυψη που της αξίζει εδώ. Για να μάθετε περισσότερα σχετικά με τη μοντελοποίηση, προτείνουμε ανεπιφύλακτα το Tidy Modeling with R από τους συναδέλφους μας Max Kuhn και Julia Silge. Αυτό το βιβλίο θα σας διδάξει την οικογένεια πακέτων tidymodels, τα οποία, όπως μπορείτε να μαντέψετε από το όνομα, μοιράζονται πολλούς κανόνες με τα πακέτα του tidyverse που χρησιμοποιούμε σε αυτό το βιβλίο.
Δεδομένα μεγάλου όγκου
Κυρίως και με υπερηφάνεια, αυτό το βιβλίο εστιάζει σε μικρά σύνολα δεδομένων με δυνατότητα να αποθηκευτούν στη μνήμη. Αυτό είναι το σωστό μέρος για να ξεκινήσετε, επειδή δεν μπορείτε να αντιμετωπίσετε δεδομένα μεγάλου όγκου εκτός εάν έχετε εμπειρία με μικρά σύνολα δεδομένων. Τα εργαλεία που θα μάθετε στο μεγαλύτερο μέρος αυτού του βιβλίου θα χειριστούν εύκολα εκατοντάδες megabyte δεδομένων και με λίγη προσοχή, μπορείτε να τα χρησιμοποιήσετε για να εργαστείτε με λίγα gigabyte δεδομένων. Θα σας δείξουμε επίσης πώς να λαμβάνετε δεδομένα από βάσεις δεδομένων και αρχεία parquet, τα οποία χρησιμοποιούνται συχνά για την αποθήκευση δεδομένων μεγάλoυ όγκου. Δεν θα μπορείτε απαραίτητα να εργαστείτε με ολόκληρο το σύνολο δεδομένων, αλλά αυτό δεν είναι πρόβλημα, επειδή χρειάζεστε μόνο ένα υποσύνολο για να απαντήσετε στην ερώτηση που σας ενδιαφέρει.
Εάν εργάζεστε τακτικά με δεδομένα μεγαλύτερου όγκου (ας πούμε 10–100 GB), συνιστούμε να μάθετε περισσότερα σχετικά με το πακέτο data.table. Δεν το μαθαίνουμε εδώ επειδή χρησιμοποιεί διαφορετική διεπαφή από το tidyverse και απαιτεί από εσάς να μάθετε μερικούς διαφορετικούς κανόνες. Ωστόσο, είναι απίστευτα ταχύτερο και αξίζει να επενδύσετε λίγο χρόνο για να το μάθετε εάν εργάζεστε με δεδομένα μεγάλου όγκου.
Python, Julia και φίλοι
Σε αυτό το βιβλίο, δεν θα μάθετε τίποτα για Python, Julia ή οποιαδήποτε άλλη γλώσσα προγραμματισμού χρήσιμη για την επιστήμη των δεδομένων. Αυτό δεν συμβαίνει επειδή πιστεύουμε ότι αυτά τα εργαλεία είναι κακά. Δεν είναι! Και στην πράξη, οι περισσότερες ομάδες επιστήμης δεδομένων χρησιμοποιούν έναν συνδυασμό γλωσσών, σε πολλές περιπτώσεις τουλάχιστον R και Python. Πιστεύουμε όμως ακράδαντα ότι είναι καλύτερο να είστε καλοί σε ένα εργαλείο τη φορά και η R είναι ένα εξαιρετικό μέρος για να ξεκινήσετε.
Προαπαιτούμενα
Κάναμε μερικές υποθέσεις σχετικά με αυτά που ήδη γνωρίζετε για να αξιοποιήσετε στο έπακρο αυτό το βιβλίο. Θα πρέπει να κατέχετε γενική αριθμητική παιδεία και είναι χρήσιμο εάν έχετε ήδη κάποια βασική εμπειρία προγραμματισμού. Εάν δεν έχετε προγραμματίσει ποτέ πριν, μπορεί να βρείτε το Hands on Programming with R του Garrett ως ένα πολύτιμο συμπλήρωμα αυτού του βιβλίου.
Χρειάζεστε τέσσερα πράγματα για να εκτελέσετε τον κώδικα σε αυτό το βιβλίο: την R, το RStudio, μία συλλογή πακέτων R που ονομάζεται tidyverse και μία μερίδα άλλων πακέτων. Τα πακέτα είναι οι θεμελιώδεις μονάδες του αναπαράξιμου κώδικα R. Περιλαμβάνουν επαναχρησιμοποιήσιμες συναρτήσεις, τεκμηρίωση που περιγράφει τον τρόπο χρήσης τους και δείγματα δεδομένων.
R
Για να κατεβάσετε την R, μεταβείτε στο CRAN, comprehensive R archive network, https://cloud.r-project.org. Μία νέα κύρια έκδοση της R κυκλοφορεί μία φορά κάθε χρόνο καθώς υπάρχουν και 2-3 μικρές εκδόσεις κάθε χρόνο. Είναι καλή ιδέα να αναβαθμίζετε τακτικά. Η αναβάθμιση μπορεί να περιέχει λίγη ταλαιπωρία, ειδικά για τις κύριες εκδόσεις που απαιτούν να εγκαταστήσετε ξανά όλα τα πακέτα σας, αλλά η αναβολή κάνει τα πράγματα μόνο χειρότερα. Προτείνουμε την R 4.2.0 ή κάποια μεταγενέστερη για αυτό το βιβλίο.
RStudio
Το RStudio είναι ένα ολοκληρωμένο περιβάλλον ανάπτυξης (integrated development environment, ή IDE), για προγραμματισμό με R, το οποίο μπορείτε να κατεβάσετε από το https://posit.co/download/rstudio-desktop/. Το RStudio ενημερώνεται μερικές φορές το χρόνο και θα σας ενημερώνει αυτόματα όταν κυκλοφορήσει μία νέα έκδοση, επομένως δεν χρειάζεται να το ελέγξετε ξανά. Είναι καλή ιδέα να κάνετε συχνές αναβαθμίσεις για να επωφεληθείτε από τις πιο πρόσφατες και καλύτερες δυνατότητες. Για αυτό το βιβλίο, βεβαιωθείτε ότι έχετε τουλάχιστον το RStudio 2022.02.0.
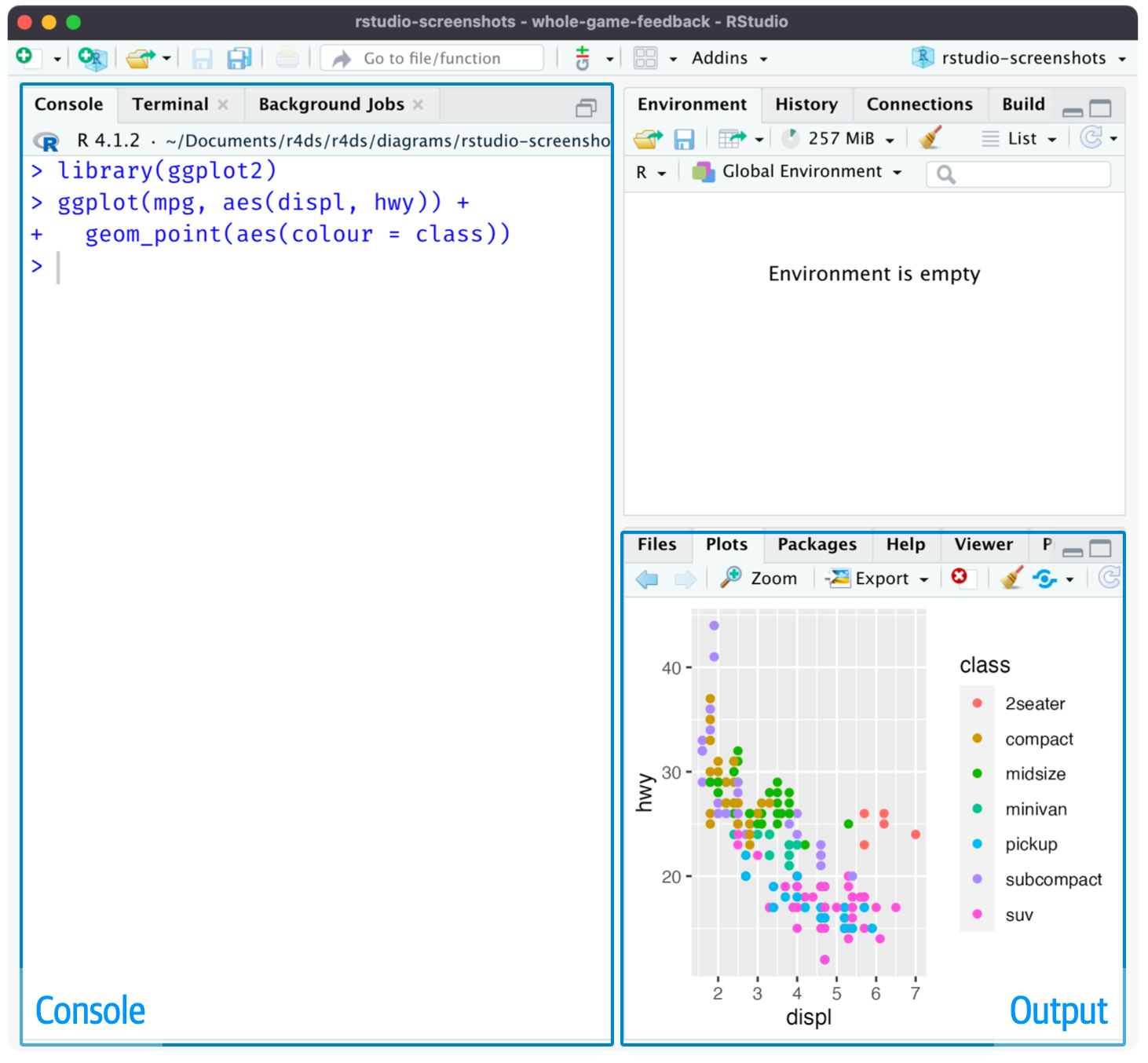
Όταν ανοίγετε το RStudio, Σχήμα 2, θα παρατηρήσετε στο περιβάλλον δύο βασικές περιοχές: το παράθυρο της κονσόλας και το παράθυρο εξόδου. Προς το παρόν, το μόνο που χρειάζεται να γνωρίζετε είναι ότι πληκτρολογείτε τον κώδικα σε R στο παράθυρο της κονσόλας και πατάτε enter για να τον εκτελέσετε. Θα μάθετε περισσότερα καθώς προχωράμε!1
Το tidyverse
Θα χρειαστεί επίσης να εγκαταστήσετε μερικά πακέτα R. Ένα πακέτο είναι μία συλλογή συναρτήσεων, δεδομένων και εγχειριδίων που επεκτείνει τις βασικές δυνατότητες της R. Η χρήση πακέτων είναι το κλειδί για την επιτυχή χρήση της R. Η πλειοψηφία των πακέτων που θα μάθετε σε αυτό το βιβλίο είναι μέρος του λεγόμενου tidyverse. Όλα τα πακέτα στο tidyverse μοιράζονται μία κοινή φιλοσοφία τύπου δεδομένων και προγραμματισμού σε R και έχουν σχεδιαστεί για να μπορούν να συνδυαστούν.
Μπορείτε να εγκαταστήσετε το πλήρες tidyverse με μία μόνο γραμμή κώδικα:
install.packages("tidyverse")Στον υπολογιστή σας, πληκτρολογήστε αυτήν τη γραμμή κώδικα στην κονσόλα και στη συνέχεια πατήστε enter για να την εκτελέσετε. Η R θα κατεβάσει τα πακέτα από το CRAN και θα τα εγκαταστήσει στον υπολογιστή σας.
Δεν θα μπορείτε να χρησιμοποιήσετε τις συναρτήσεις, τα αντικείμενα ή τα έγγραφα βοήθειας σε ένα πακέτο μέχρι να το φορτώσετε με τη συνάρτηση library(). Αφού εγκαταστήσετε ένα πακέτο, μπορείτε να το φορτώσετε χρησιμοποιώντας τη συνάρτηση library():
library(tidyverse)
#> ── Attaching core tidyverse packages ───────────────────── tidyverse 2.0.0 ──
#> ✔ dplyr 1.1.4 ✔ readr 2.1.5
#> ✔ forcats 1.0.0 ✔ stringr 1.5.1
#> ✔ ggplot2 3.5.0 ✔ tibble 3.2.1
#> ✔ lubridate 1.9.3 ✔ tidyr 1.3.1
#> ✔ purrr 1.0.2
#> ── Conflicts ─────────────────────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsΑυτό σας λέει ότι το tidyverse φορτώνει εννέα πακέτα: dplyr, forcats, ggplot2, lubridate, purrr, readr, stringr, tibble, tidyr. Αυτά θεωρούνται ο πυρήνας του tidyverse, καθώς θα τα χρησιμοποιείτε σχεδόν σε κάθε ανάλυση.
Τα πακέτα στο tidyverse αλλάζουν αρκετά συχνά. Μπορείτε να δείτε εάν υπάρχουν διαθέσιμες ενημερώσεις εκτελώντας tidyverse_update().
Άλλα πακέτα
Υπάρχουν πολλά άλλα εξαιρετικά πακέτα που δεν αποτελούν μέρος του tidyverse μιας και επιλύουν προβλήματα που ανοίγουν σε διαφορετικούς τομείς ή έχουν σχεδιαστεί με ένα διαφορετικό σύνολο βασικών αρχών. Αυτό δεν τα κάνει καλύτερα ή χειρότερα - απλά τα κάνει διαφορετικά. Με άλλα λόγια, το συμπληρωματικό κομμάτι του tidyverse δεν είναι το messyverse, αλλά άλλοι κόσμοι (universes) αλληλένδετων πακέτων. Καθώς αντιμετωπίζετε περισσότερα έργα επιστήμης δεδομένων με την R, θα μάθετε νέα πακέτα και νέους τρόπους σκέψης που σχετίζονται με δεδομένα.
Σε αυτό το βιβλίο θα χρησιμοποιήσουμε πολλά πακέτα εκτός του tidyverse. Για παράδειγμα, θα χρησιμοποιήσουμε τα ακόλουθα πακέτα επειδή παρέχουν ενδιαφέροντα σύνολα δεδομένων για τη διαδικασία εκμάθησης της R:
install.packages(
c("arrow", "babynames", "curl", "duckdb", "gapminder",
"ggrepel", "ggridges", "ggthemes", "hexbin", "janitor", "Lahman",
"leaflet", "maps", "nycflights13", "openxlsx", "palmerpenguins",
"repurrrsive", "tidymodels", "writexl")
)Θα χρησιμοποιήσουμε επίσης μία επιλογή από άλλα πακέτα για μεμονωμένα παραδείγματα. Δεν χρειάζεται να τα εγκαταστήσετε τώρα, απλά να θυμάστε ότι κάθε φορά που βλέπετε ένα σφάλμα όπως αυτό:
Θα πρέπει να εκτελέσετε install.packages("ggrepel") για να εγκαταστήσετε το πακέτο.
Εκτελώντας κώδικα R
Η προηγούμενη ενότητα σας έδειξε αρκετά παραδείγματα εκτέλεσης κώδικα R. Ο κώδικας στο βιβλίο δείχνει κάπως έτσι:
1 + 2
#> [1] 3Αν εκτελέσετε τον ίδιο κώδικα στο πεδίο της κονσόλας σας, θα δείχνει κάπως έτσι:
> 1 + 2
[1] 3Υπάρχουν δύο βασικές διαφορές. Στην κονσόλα σας, πληκτρολογείτε (τον κώδικα) μετά το >, που ονομάζεται εντολή. Δεν δείχνουμε την εντολή στο βιβλίο. Στο βιβλίο, η έξοδος αφαιρείται τοποθετώντας τη ως σχόλιο με #>. Στην κονσόλα σας, εμφανίζεται αμέσως μετά τον κώδικά σας. Αυτές οι δύο διαφορές σημαίνουν ότι εάν εργάζεστε με μία ηλεκτρονική έκδοση του βιβλίου, μπορείτε εύκολα να αντιγράψετε κώδικα από το βιβλίο και να τον επικολλήσετε στην κονσόλα.
Σε όλο το βιβλίο, χρησιμοποιούμε ένα συνεπές σύνολο κανόνων για να αναφερθούμε στον κώδικα:
Οι συναρτήσεις εμφανίζονται σε μία γραμματοσειρά κώδικα και ακολουθούνται από παρενθέσεις, όπως
sum()ήmean().Άλλα αντικείμενα R (όπως ορίσματα δεδομένων ή συναρτήσεων) είναι σε γραμματοσειρά κώδικα, χωρίς παρενθέσεις, όπως
flightsήx.Μερικές φορές, για να ξεκαθαρίσουμε από ποιο πακέτο προέρχεται ένα αντικείμενο, θα χρησιμοποιήσουμε το όνομα του πακέτου ακολουθούμενο από δύο άνω και κάτω τελείες, όπως
dplyr::mutate()ήnycflights13::flights. Αυτός ο κώδικας R είναι επίσης έγκυρος.
Ευχαριστίες
Αυτό το βιβλίο δεν είναι μόνο προϊόν των Hadley, Mine και Garrett, αλλά είναι το αποτέλεσμα πολλών συζητήσεων (δια ζώσης και διαδικτυακών) που είχαμε με πολλά άτομα μέσα από την κοινότητα της R. Είμαστε απίστευτα ευγνώμονες για όλες τις συζητήσεις που είχαμε μαζί σας. Σας ευχαριστούμε πάρα πολύ!
Αυτό το βιβλίο είναι γραμμένο απο κοινού με πολλά άτομα να έχουν συμβάλλει μέσω pull requests. Ένα μεγάλο ευχαριστώ σε όλους 259 εσάς που κατέθεσατε βελτιώσεις μέσω pull requests του GitHub (με αλφαβητική σειρα ανα όνομα χρήστη): @a-rosenberg, Tim Becker (@a2800276), Abinash Satapathy (@Abinashbunty), Adam Gruer (@adam-gruer), adi pradhan (@adidoit), A. s. (@Adrianzo), Aep Hidyatuloh (@aephidayatuloh), Andrea Gilardi (@agila5), Ajay Deonarine (@ajay-d), @AlanFeder, Daihe Sui (@alansuidaihe), @alberto-agudo, @AlbertRapp, @aleloi, pete (@alonzi), Alex (@ALShum), Andrew M. (@amacfarland), Andrew Landgraf (@andland), @andyhuynh92, Angela Li (@angela-li), Antti Rask (@AnttiRask), LOU Xun (@aquarhead), @ariespirgel, @august-18, Michael Henry (@aviast), Azza Ahmed (@azzaea), Steven Moran (@bambooforest), Brian G. Barkley (@BarkleyBG), Mara Averick (@batpigandme), Oluwafemi OYEDELE (@BB1464), Brent Brewington (@bbrewington), Bill Behrman (@behrman), Ben Herbertson (@benherbertson), Ben Marwick (@benmarwick), Ben Steinberg (@bensteinberg), Benjamin Yeh (@bentyeh), Betul Turkoglu (@betulturkoglu), Brandon Greenwell (@bgreenwell), Bianca Peterson (@BinxiePeterson), Birger Niklas (@BirgerNi), Brett Klamer (@bklamer), @boardtc, Christian (@c-hoh), Caddy (@caddycarine), Camille V Leonard (@camillevleonard), @canovasjm, Cedric Batailler (@cedricbatailler), Christina Wei (@christina-wei), Christian Mongeau (@chrMongeau), Cooper Morris (@coopermor), Colin Gillespie (@csgillespie), Rademeyer Vermaak (@csrvermaak), Chloe Thierstein (@cthierst), Chris Saunders (@ctsa), Abhinav Singh (@curious-abhinav), Curtis Alexander (@curtisalexander), Christian G. Warden (@cwarden), Charlotte Wickham (@cwickham), Kenny Darrell (@darrkj), David Kane (@davidkane9), David (@davidrsch), David Rubinger (@davidrubinger), David Clark (@DDClark), Derwin McGeary (@derwinmcgeary), Daniel Gromer (@dgromer), @Divider85, @djbirke, Danielle Navarro (@djnavarro), Russell Shean (@DOH-RPS1303), Zhuoer Dong (@dongzhuoer), Devin Pastoor (@dpastoor), @DSGeoff, Devarshi Thakkar (@dthakkar09), Julian During (@duju211), Dylan Cashman (@dylancashman), Dirk Eddelbuettel (@eddelbuettel), Edwin Thoen (@EdwinTh), Ahmed El-Gabbas (@elgabbas), Henry Webel (@enryH), Ercan Karadas (@ercan7), Eric Kitaif (@EricKit), Eric Watt (@ericwatt), Erik Erhardt (@erikerhardt), Etienne B. Racine (@etiennebr), Everett Robinson (@evjrob), @fellennert, Flemming Miguel (@flemmingmiguel), Floris Vanderhaeghe (@florisvdh), @funkybluehen, @gabrivera, Garrick Aden-Buie (@gadenbuie), Peter Ganong (@ganong123), Gerome Meyer (@GeroVanMi), Gleb Ebert (@gl-eb), Josh Goldberg (@GoldbergData), bahadir cankardes (@gridgrad), Gustav W Delius (@gustavdelius), Hao Chen (@hao-trivago), Harris McGehee (@harrismcgehee), @hendrikweisser, Hengni Cai (@hengnicai), Iain (@Iain-S), Ian Sealy (@iansealy), Ian Lyttle (@ijlyttle), Ivan Krukov (@ivan-krukov), Jacob Kaplan (@jacobkap), Jazz Weisman (@jazzlw), John Blischak (@jdblischak), John D. Storey (@jdstorey), Gregory Jefferis (@jefferis), Jeffrey Stevens (@JeffreyRStevens), 蒋雨蒙 (@JeldorPKU), Jennifer (Jenny) Bryan (@jennybc), Jen Ren (@jenren), Jeroen Janssens (@jeroenjanssens), @jeromecholewa, Janet Wesner (@jilmun), Jim Hester (@jimhester), JJ Chen (@jjchern), Jacek Kolacz (@jkolacz), Joanne Jang (@joannejang), @johannes4998, John Sears (@johnsears), @jonathanflint, Jon Calder (@jonmcalder), Jonathan Page (@jonpage), Jon Harmon (@jonthegeek), JooYoung Seo (@jooyoungseo), Justinas Petuchovas (@jpetuchovas), Jordan (@jrdnbradford), Jeffrey Arnold (@jrnold), Jose Roberto Ayala Solares (@jroberayalas), Joyce Robbins (@jtr13), @juandering, Julia Stewart Lowndes (@jules32), Sonja (@kaetschap), Kara Woo (@karawoo), Katrin Leinweber (@katrinleinweber), Karandeep Singh (@kdpsingh), Kevin Perese (@kevinxperese), Kevin Ferris (@kferris10), Kirill Sevastyanenko (@kirillseva), Jonathan Kitt (@KittJonathan), @koalabearski, Kirill Müller (@krlmlr), Rafał Kucharski (@kucharsky), Kevin Wright (@kwstat), Noah Landesberg (@landesbergn), Lawrence Wu (@lawwu), @lindbrook, Luke W Johnston (@lwjohnst86), Kara de la Marck (@MarckK), Kunal Marwaha (@marwahaha), Matan Hakim (@matanhakim), Matthias Liew (@MatthiasLiew), Matt Wittbrodt (@MattWittbrodt), Mauro Lepore (@maurolepore), Mark Beveridge (@mbeveridge), @mcewenkhundi, mcsnowface, PhD (@mcsnowface), Matt Herman (@mfherman), Michael Boerman (@michaelboerman), Mitsuo Shiota (@mitsuoxv), Matthew Hendrickson (@mjhendrickson), @MJMarshall, Misty Knight-Finley (@mkfin7), Mohammed Hamdy (@mmhamdy), Maxim Nazarov (@mnazarov), Maria Paula Caldas (@mpaulacaldas), Mustafa Ascha (@mustafaascha), Nelson Areal (@nareal), Nate Olson (@nate-d-olson), Nathanael (@nateaff), @nattalides, Ned Western (@NedJWestern), Nick Clark (@nickclark1000), @nickelas, Nirmal Patel (@nirmalpatel), Nischal Shrestha (@nischalshrestha), Nicholas Tierney (@njtierney), Jakub Nowosad (@Nowosad), Nick Pullen (@nstjhp), @olivier6088, Olivier Cailloux (@oliviercailloux), Robin Penfold (@p0bs), Pablo E. Garcia (@pabloedug), Paul Adamson (@padamson), Penelope Y (@penelopeysm), Peter Hurford (@peterhurford), Peter Baumgartner (@petzi53), Patrick Kennedy (@pkq), Pooya Taherkhani (@pooyataher), Y. Yu (@PursuitOfDataScience), Radu Grosu (@radugrosu), Ranae Dietzel (@Ranae), Ralph Straumann (@rastrau), Rayna M Harris (@raynamharris), @ReeceGoding, Robin Gertenbach (@rgertenbach), Jajo (@RIngyao), Riva Quiroga (@rivaquiroga), Richard Knight (@RJHKnight), Richard Zijdeman (@rlzijdeman), @robertchu03, Robin Kohrs (@RobinKohrs), Robin (@Robinlovelace), Emily Robinson (@robinsones), Rob Tenorio (@robtenorio), Rod Mazloomi (@RodAli), Rohan Alexander (@RohanAlexander), Romero Morais (@RomeroBarata), Albert Y. Kim (@rudeboybert), Saghir (@saghirb), Hojjat Salmasian (@salmasian), Jonas (@sauercrowd), Vebash Naidoo (@sciencificity), Seamus McKinsey (@seamus-mckinsey), @seanpwilliams, Luke Smith (@seasmith), Matthew Sedaghatfar (@sedaghatfar), Sebastian Kraus (@sekR4), Sam Firke (@sfirke), Shannon Ellis (@ShanEllis), @shoili, Christian Heinrich (@Shurakai), S’busiso Mkhondwane (@sibusiso16), SM Raiyyan (@sm-raiyyan), Jakob Krigovsky (@sonicdoe), Stephan Koenig (@stephan-koenig), Stephen Balogun (@stephenbalogun), Steven M. Mortimer (@StevenMMortimer), Stéphane Guillou (@stragu), Sulgi Kim (@sulgik), Sergiusz Bleja (@svenski), Tal Galili (@talgalili), Alec Fisher (@Taurenamo), Todd Gerarden (@tgerarden), Tom Godfrey (@thomasggodfrey), Tim Broderick (@timbroderick), Tim Waterhouse (@timwaterhouse), TJ Mahr (@tjmahr), Thomas Klebel (@tklebel), Tom Prior (@tomjamesprior), Terence Teo (@tteo), @twgardner2, Ulrik Lyngs (@ulyngs), Shinya Uryu (@uribo), Martin Van der Linden (@vanderlindenma), Walter Somerville (@waltersom), @werkstattcodes, Will Beasley (@wibeasley), Yihui Xie (@yihui), Yiming (Paul) Li (@yimingli), @yingxingwu, Hiroaki Yutani (@yutannihilation), Yu Yu Aung (@yuyu-aung), Zach Bogart (@zachbogart), @zeal626, Zeki Akyol (@zekiakyol).
Κολοφώνας
Μία ηλεκτρονική έκδοση αυτού του βιβλίου είναι διαθέσιμη στη διεύθυνση https://r4ds.hadley.nz. Θα συνεχίσει να εξελίσσεται μεταξύ των αναθεωρήσεων του φυσικού βιβλίου. Ο πηγαίος κώδικας του βιβλίου είναι διαθέσιμος στη διεύθυνση https://github.com/hadley/r4ds. Το βιβλίο δημιουργήθηκε με Quarto, το οποίο διευκολύνει τη σύνταξη βιβλίων που συνδυάζουν κείμενο και εκτελέσιμο κώδικα.
Εάν θέλετε μία ολοκληρωμένη επισκόπηση όλων των δυνατοτήτων του RStudio, ανατρέξτε στον αντίστοιχο Οδηγό Χρήστη στη διεύθυνση https://docs.posit.co/ide/user.↩︎