4 Ροή εργασιών: πρότυπα γραφής κώδικα
Ένα καλό πρότυπο γραφής κώδικα μοιάζει με τα σωστά σημεία στίξης: μπορείτε να επιβιώσετε χωρίς αυτό, αλλά σίγουρακάνειτηνανάγνωσηπιοεύκολη. Ακόμη και ως πολύ νέος προγραμματιστής, είναι καλή ιδέα να δουλέψετε πάνω στοn τρόπο σύνταξης του κώδικα σας. Η χρήση ενός σταθερού τρόπου ύνταξης διευκολύνει τους άλλους (συμπεριλαμβανομένου του μελλοντικού σας εαυτού) να διαβάσουν τη δουλειά σας και είναι ιδιαίτερα σημαντικό εάν χρειαστεί να λάβετε βοήθεια από κάποιον άλλο. Αυτό το κεφάλαιο θα παρουσιάσει τα πιο σημαντικά σημεία του tidyverse style guide, το οποίο χρησιμοποιείται σε αυτό το βιβλίο.
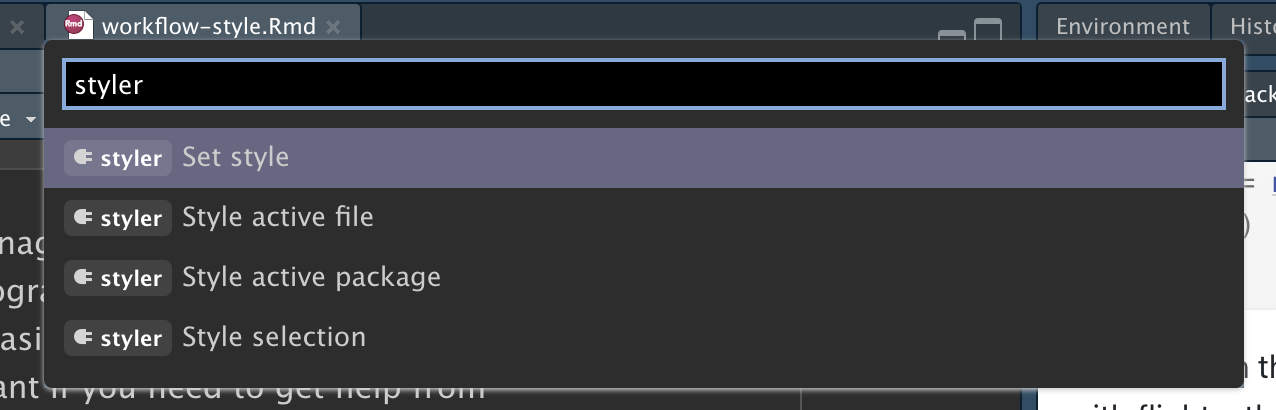
Η οργάνωση του κώδικά σας θα είναι λίγο κουραστική στην αρχή, αλλά εαν εξασκηθείτε, σύντομα θα γίνει συνήθεια. Επιπλέον, υπάρχουν μερικά εξαιρετικά εργαλεία για γρήγορη αναδιαμόρφωση του υπάρχοντος κώδικα, όπως το πακέτο styler από τον Lorenz Walthert. Αφού το εγκαταστήσετε με το install.packages("styler"), ένας εύκολος τρόπος να το χρησιμοποιήσετε είναι μέσω της παλέτας εντολών (command palette) του RStudio. Η παλέτα εντολών σας επιτρέπει να χρησιμοποιείτε οποιαδήποτε ενσωματωμένη εντολή του RStudio, καθώς και πολλά πρόσθετα που παρέχονται από πακέτα. Ανοίξτε την παλέτα πατώντας Cmd/Ctrl + Shift + P και μετά πληκτρολογήστε “styler” για να δείτε όλες τις συντομεύσεις που προσφέρει ο styler. Το Σχήμα 4.1 δείχνει τα αποτελέσματα.
Θα χρησιμοποιήσουμε τα πακέτα tidyverse και nycflights13 για παραδείγματα κώδικα σε αυτό το κεφάλαιο.
4.1 Ονόματα
Μιλήσαμε εν συντομία για ονόματα στην Ενότητα 2.3. Να θυμάστε ότι τα ονόματα μεταβλητών (αυτά που δημιουργούνται από το <- και αυτά που δημιουργούνται από τη mutate()) θα πρέπει να χρησιμοποιούν μόνο πεζά γράμματα, αριθμούς και _. Μέσα σε ένα όνομα χρησιμοποιούμε το _ για να διαχωρίσουμε λέξεις μεταξύ τους.
Ως γενικός εμπειρικός κανόνας, είναι καλύτερο να προτιμάτε μεγάλα, περιγραφικά ονόματα που είναι εύκολα κατανοητά παρά συνοπτικά ονόματα που είναι γρήγορα στην πληκτρολόγηση. Τα σύντομα ονόματα εξοικονομούν σχετικά λίγο χρόνο κατά τη σύνταξη κώδικα (ειδικά επειδή η αυτόματη συμπλήρωση θα σας βοηθήσει να ολοκληρώσετε την πληκτρολόγηση), αλλά μπορεί να είναι χρονοβόρο να αποκρυπτογραφήσετε τι εννοούσατε όταν επιστρέψετε σε παλιό κώδικα.
Εάν έχετε ένα σωρό ονόματα για σχετικά πράγματα, προσπαθήστε να είστε συνεπείς. Είναι εύκολο να προκύψουν ασυνέπειες όταν ξεχνάτε έναν προηγούμενο κανόνα, οπότε μην αισθάνεστε άσχημα αν πρέπει να επιστρέψετε και να μετονομάσετε κάποια πράγματα. Γενικά, αν έχετε ένα σύνολο μεταβλητών που αποτελούν παραλλαγή ενός θέματος, είναι προτιμότερο να τους δώσετε ένα κοινό πρόθεμα αντί για ένα κοινό επίθημα, επειδή η αυτόματη συμπλήρωση λειτουργεί καλύτερα στην αρχή μιας μεταβλητής.
4.2 Διαστήματα
Τοποθετήστε κενά σε κάθε πλευρά των μαθηματικών τελεστών εκτός από το ^ (δηλαδή στα +, -, ==, <, …) και γύρω από τον τελεστή ανάθεσης (<-).
# Προσπαθήστε για:
z <- (a + b)^2 / d
# Αποφύγετε:
z<-( a + b ) ^ 2/dΜην βάζετε κενά μέσα ή έξω από παρενθέσεις για κανονικές κλήσεις συναρτήσεων. Να βάζετε πάντα ένα κενό μετά το κόμμα, όπως και στα ελληνικά.
Είναι εντάξει να προσθέσετε επιπλέον κενά εάν αυτό βελτιώνει τη διάταξη του κώδικα. Για παράδειγμα, εάν δημιουργείτε πολλές μεταβλητές στη mutate(), ίσως θέλετε να προσθέσετε κενά έτσι ώστε όλα τα = να ευθυγραμμιστούν.1 Αυτό διευκολύνει το γρήγορο διάβασμα του κώδικα.
4.3 Pipes
Το |> θα πρέπει πάντα να έχει ένα κενό πριν από αυτό και θα πρέπει να είναι το τελευταίο πράγμα σε μία γραμμή. Αυτό διευκολύνει την προσθήκη νέων βημάτων, την αναδιάταξη των υπαρχόντων βημάτων, την τροποποίηση στοιχείων μέσα σε ένα βήμα και τη λήψη μιας προβολής 10.000 ποδιών, διαβάζοντας γρήγορα τις συναρτήσεις στην αριστερή πλευρά.
Εάν η συνάρτηση στην οποία εισάγετε έχει ορίσματα με όνομα (όπως οι mutate() ή summarize(), βάλτε κάθε όρισμα σε μία νέα γραμμή. Εάν η συνάρτηση δεν έχει ορίσματα με όνομα (όπως οι select() ή filter()), κρατήστε τα πάντα σε μία γραμμή εκτός εάν δεν χωράνε, οπότε θα πρέπει να βάλετε κάθε όρισμα στη δική του γραμμή.
Μετά το πρώτο βήμα της διαδικασίας, εισάγετε σε κάθε γραμμή μία εσοχή, προσθέτοντας δύο κενά. Το RStudio θα τοποθετήσει αυτόματα τα κενά για εσάς κατά την αλλαγή γραμμής μετά από ένα |> . Εάν τοποθετείτε κάθε όρισμα στη δική του γραμμή, αυξήστε την εσοχή κατά δύο επιπλέον κενά. Βεβαιωθείτε ότι το ) βρίσκεται στη δική του γραμμή και δεν έχει εσοχές ώστε να ταιριάζει με την οριζόντια θέση του ονόματος της συνάρτησης.
# Προσπαθήστε για:
flights |>
group_by(tailnum) |>
summarize(
delay = mean(arr_delay, na.rm = TRUE),
n = n()
)
# Αποφύγετε:
flights|>
group_by(tailnum) |>
summarize(
delay = mean(arr_delay, na.rm = TRUE),
n = n()
)
# Αποφύγετε:
flights|>
group_by(tailnum) |>
summarize(
delay = mean(arr_delay, na.rm = TRUE),
n = n()
)Είναι εντάξει να αποφύγετε μερικούς από αυτούς τους κανόνες, εάν η διαδικασία που θέλετε να εκτελέσετε ταιριάζει εύκολα σε μία γραμμή. Ωστόσο, στη συλλογική μας εμπειρία, είναι σύνηθες τα μικρά αποσπάσματα κώδικα να μεγαλώνουν περισσότερο, επομένως συνήθως θα εξοικονομείτε χρόνο μακροπρόθεσμα ξεκινώντας με όλο τον κατακόρυφο χώρο που χρειάζεστε.
Τέλος, να είστε προσεκτικοί όταν γράφετε εκτεταμένους συνδυασμούς συναρτήσεων που συνδέονται με pipes, για παράδειγμα πάνω από 10-15 γραμμές. Προσπαθήστε να τις χωρίσετε σε μικρότερες δευτερεύουσες εργασίες, δίνοντας σε κάθε εργασία ένα ενημερωτικό όνομα. Τα ονόματα θα βοηθήσουν τον αναγνώστη να καταλάβει τι συμβαίνει και θα διευκολύνει τον έλεγχο του ότι τα ενδιάμεσα αποτελέσματα είναι τα αναμενόμενα. Είναι καλό να δίνετε σε κάτι ένα ενημερωτικό όνομα κάθε φορά που έχετε αυτή τη δυνατότητα, για παράδειγμα όταν αλλάζετε ριζικά τη δομή των δεδομένων, π.χ. μετά από την δημιουργία κάποιου συγκεντρωτικού πίνακα ή σύνοψης. Μην περιμένετε να το κάνετε σωστά την πρώτη φορά! Αυτό σημαίνει διάλυση μεγάλων ροών σε περίπτωση που υπάρχουν ενδιάμεσες καταστάσεις που μπορούν να λάβουν καλά ονόματα.
4.4 ggplot2
Οι ίδιοι βασικοί κανόνες που ισχύουν για τις συναρτήσεις που συνδέονται με pipes ισχύουν και στην περίπτωση της ggplot2. Απλώς αντιμετωπίστε το + με τον ίδιο τρόπο όπως και το |>.
Και πάλι, εάν δεν μπορείτε να χωρέσετε όλα τα ορίσματα μιας συνάρτησης σε μία γραμμή, βάλτε κάθε όρισμα στη δική του γραμμή:
flights |>
group_by(dest) |>
summarize(
distance = mean(distance),
speed = mean(distance / air_time, na.rm = TRUE)
) |>
ggplot(aes(x = distance, y = speed)) +
geom_smooth(
method = "loess",
span = 0.5,
se = FALSE,
color = "white",
linewidth = 4
) +
geom_point()Παρακολουθήστε τη μετάβαση από το |> στο +. Μακάρι αυτή η μετάβαση να μην ήταν απαραίτητη, αλλά δυστυχώς, το πακέτο ggplot2 γράφτηκε πριν την εισαγωγή του pipe.
4.5 Τμηματοποίηση σχολίων
Καθώς τα αρχεία κώδικα σας μεγαλώνουν, μπορείτε να χρησιμοποιήσετε σχόλια τμηματοποίησης για να χωρίσετε το αρχείο σας σε διαχειρίσιμα κομμάτια:
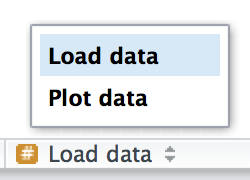
# Load data --------------------------------------
# Plot data --------------------------------------Το RStudio παρέχει μία συντόμευση για τη δημιουργία αυτών των κεφαλίδων (Cmd/Ctrl + Shift + R) και θα τις εμφανίσει στο αναπτυσσόμενο μενού πλοήγησης κώδικα στο κάτω αριστερό μέρος του προγράμματος επεξεργασίας, όπως φαίνεται στο Σχήμα 4.2.
4.6 Ασκήσεις
-
Προσαρμόστε τις ακόλουθες ροές εργασιών, ακολουθώντας τις παραπάνω οδηγίες.
flights|>filter(dest=="IAH")|>group_by(year,month,day)|>summarize(n=n(), delay=mean(arr_delay,na.rm=TRUE))|>filter(n>10) flights|>filter(carrier=="UA",dest%in%c("IAH","HOU"),sched_dep_time> 0900,sched_arr_time<2000)|>group_by(flight)|>summarize(delay=mean( arr_delay,na.rm=TRUE),cancelled=sum(is.na(arr_delay)),n=n())|>filter(n>10)
4.7 Σύνοψη
Σε αυτό το κεφάλαιο, έχετε μάθει τις πιο σημαντικές αρχές οργάνωσης του κώδικα σας. Αυτοί μπορεί να φαίνονται σαν ένα σύνολο αυθαίρετων κανόνων για αρχή (γιατί είναι!), αλλά με την πάροδο του χρόνου, καθώς γράφετε περισσότερο κώδικα και μοιράζεστε κώδικα με περισσότερα άτομα, θα δείτε πόσο σημαντικό είναι ένα σταθερό στυλ/τρόπος γραφής. Και μην ξεχνάτε το πακέτο styler: είναι ένας πολύ καλός τρόπος για να βελτιώσετε γρήγορα την ποιότητα κακοδομημένου κώδικα.
Στο επόμενο κεφάλαιο, επιστρέφουμε στα εργαλεία που χρησιμοποιούνται στην επιστήμη δεδομένων, μαθαίνοντας για τα τακτοποιημένα (tidy) δεδομένα. Τα τακτοποιημένα δεδομένα είναι ένας συνεπής τρόπος οργάνωσης των πλαισίων δεδομένων σας που χρησιμοποιείται στο tidyverse. Αυτή η συνέπεια κάνει τη ζωή σας πιο εύκολη, επειδή μόλις έχετε τακτοποιημένα δεδομένα, είναι συμβατά με τη συντριπτική πλειοψηφία των συναρτήσεων του tidyverse. Φυσικά, η ζωή δεν είναι ποτέ εύκολη και τα περισσότερα σύνολα δεδομένων που συναντάτε δεν θα είναι ήδη τακτοποιημένα. Έτσι, θα σας μάθουμε επίσης πώς να χρησιμοποιείτε το πακέτο tidyr για να τακτοποιείτε τα ακατάστατα δεδομένα σας.
Μιας και η
dep_timeείναι σε μορφήHMMήHHMM, χρησιμοποιούμε διαίρεση ακέραιων αριθμών (%/%) για να λάβουμε ώρες και το υπόλοιπο (επίσης γνωστό ως modulo,%%) για να πάρετε λεπτά.↩︎